Creating a Voice Activated CoffeeShop in .NET


In Part 1 of our GPT CoffeeShop in .NET we looked at how we could easily implement a TypeChat's CoffeeShop Application Database and Management UI which was able to dynamically generate TypeChat's coffeeShopSchema.ts in .NET using:
- CoffeeShopPromptProvider.cs:
To create the
ScriptContextcontaining all data and functionality our #Script is executed with - /coffeeshop/schema.ss: #Script Template that generates the TypeScript Schema
The result of which produces a functionally equivalent /coffeeshop/schema.ts powered by the data in CoffeeShop's Database.
CoffeeShop .NET App
The purpose of which is to implement a CoffeeShop Menu which can fulfil ordering any of the products along with any toppings, customizations and preparation options listed by the App's database and resulting TypeScript Schema.
The resulting App implements a standard Web UI to navigate all categories and products offered in the CoffeeShop Menu,
that also supports an Audio Input letting customers order from the Menu using their Voice - which relies on Open AI's
GPT services utilising Microsoft's TypeChat schema prompt and node library
to convert a natural language order into a Cart order our App can understand, you can try at:
https://coffeeshop.netcore.io
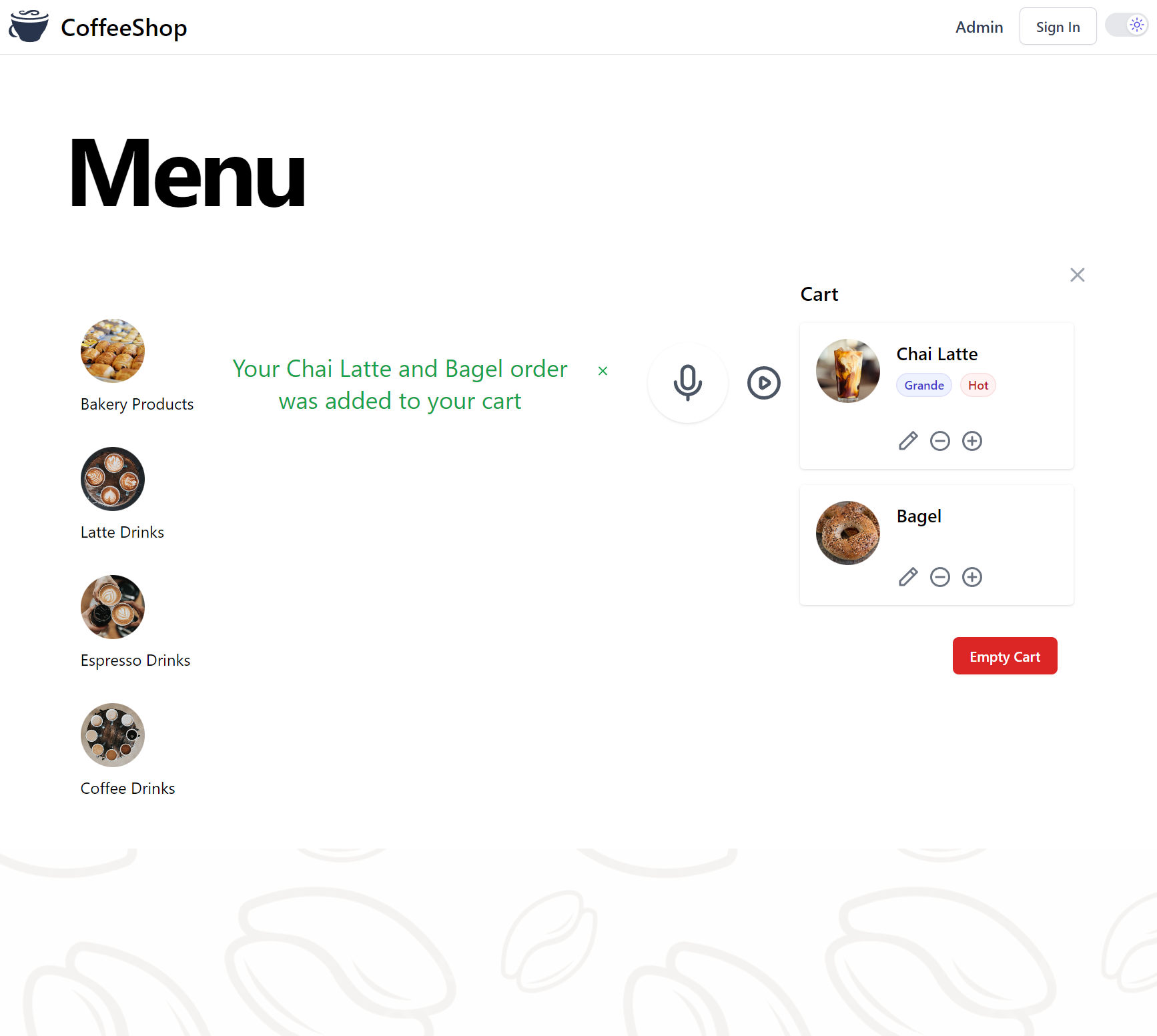
source https://github.com/NetCoreApps/CoffeeShop
The Web UI adopts the same build-free Simple, Modern JavaScript approach used to create blazor-vue's Client Admin UI, to create the CoffeeShop's reactive frontend UI utilizing progressive Vue.mjs, which is maintained in the Index.cshtml Home page.
This post explains how we implemented this functionality in .NET along with the different providers you can use to transcribe audio recordings, save uploaded files and use GPT to convert natural language to order item requests we can add to our cart.
Implementing Voice Command Customer Orders
Before we're able to enlist Chat GPT to do our bidding for us, we need to capture our Customer's CoffeeShop Order Voice Recording and transcribe it to text.
We have a few options when it comes to real-time Speech-to-Text translation services you can choose from, including:
- Google Cloud Speech-to-Text - Starts from $0.016 /minute or $0.012 if you're ok with Google to use your recordings to improve their AI models
- Amazon Transcribe - Starts from $0.024 /minute
- Azure AI Speech - Starts from $0.0167 /minute
- OpenAI Whisper API - Flat rate of $0.006 /minute for using their online API
- OpenAI Whisper Local - Whisper is also available as an OSS project you can run yourself if you prefer to manage your own servers and local Whisper install
ServiceStack.AI Providers
As the AI landscape is actively changing we want our Apps to be able to easily switch to different Speech-to-text providers so we're able to evaluate and use the best provider for each use-case.
To support this we're maintaining FREE implementation-agnostic abstractions for different AI and GPT Providers to enable AI features in .NET Apps under the new ServiceStack.AI namespace in our dependency-free ServiceStack.Interfaces package.
Where the implementations for these abstractions are maintained across the following NuGet packages according to their required dependencies:
ServiceStack.Aws- AI & GPT Providers for Amazon Web ServicesServiceStack.Azure- AI & GPT Providers for Microsoft AzureServiceStack.GoogleCloud- AI & GPT Providers for Google CloudServiceStack.AI- AI & GPT Providers for OpenAI APIs and local Whisper and Node TypeChat installs
These free abstractions and implementations allow .NET project's to decouple their Speech-to-text or ChatGPT requirements from any single implementation where they can be easily substituted.
You're welcome to submit feature requests for other providers you'd like to see at:
https://servicestack.net/ideas
ISpeechToText
The ISpeechToText interface abstracts Speech-to-text services behind a simple API:
public interface ISpeechToText
{
// Once only task to run out-of-band before using the SpeechToText provider
Task InitAsync(List<string> phrases, CancellationToken token = default);
// Transcribe the Audio at recordingPath and return a JSON API Result
Task<TranscriptResult> TranscribeAsync(string request, CancellationToken token);
}
As of this of this writing CoffeeShop supports using 5 different Speech-to-text providers, defaulting to using Open AI's Whisper API:
GoogleCloudSpeechToText- to use Google Cloud's Speech-to-Text v2 APIAwsSpeechToText- to use Amazon Transcribe APIAzureSpeechToText- to use Azure Speech to text APIWhisperApiSpeechToText- to use OpenAI's Whisper APIWhisperLocalSpeechToText- to use local install of OpenAI Whisper
CoffeeShop can use any of these providers by configuring it in appsettings.json:
{
"SpeechProvider": "WhisperApiSpeechToText"
}
Where all available providers are configured in Configure.Speech.cs:
var speechProvider = context.Configuration.GetValue<string>("SpeechProvider");
if (speechProvider == nameof(GoogleCloudSpeechToText))
{
services.AddSingleton<ISpeechToText>(c => {
var config = c.Resolve<AppConfig>();
var gcp = c.Resolve<GoogleCloudConfig>();
return new GoogleCloudSpeechToText(SpeechClient.Create(),
gcp.ToSpeechToTextConfig(x => {
x.PhraseSetId = config.CoffeeShop.PhraseSetId;
x.RecognizerId = config.CoffeeShop.RecognizerId;
})
);
});
}
else if (speechProvider == nameof(AwsSpeechToText))
{
services.AddSingleton<ISpeechToText>(c => {
var config = c.Resolve<AppConfig>();
var aws = c.Resolve<AwsConfig>();
return new AwsSpeechToText(new AmazonTranscribeServiceClient(
aws.AccessKey, aws.SecretKey, aws.ToRegionEndpoint()),
aws.ToSpeechToTextConfig(x =>
x.VocabularyName = config.CoffeeShop.VocabularyName));
});
}
else if (speechProvider == nameof(AzureSpeechToText))
{
services.AddSingleton<ISpeechToText>(c => {
var azure = c.Resolve<AzureConfig>();
return new AzureSpeechToText(azure.ToSpeechConfig());
});
}
else if (speechProvider == nameof(WhisperApiSpeechToText))
{
services.AddSingleton<ISpeechToText, WhisperApiSpeechToText>();
}
else if (speechProvider == nameof(WhisperLocalSpeechToText))
{
services.AddSingleton<ISpeechToText>(c => new WhisperLocalSpeechToText {
WhisperPath = c.Resolve<AppConfig>().WhisperPath,
TimeoutMs = c.Resolve<AppConfig>().NodeProcessTimeoutMs,
});
}
CoffeeShop OpenAI Defaults
To support a minimal infrastructure dependency solution the CoffeeShop GitHub Repo is configured by default to use OpenAI's Whisper API to transcribe recordings that are persisted to local disk.
Which at a minimum to use CoffeeShop's text or voice activated commands needs the OPENAI_API_KEY Environment Variable
configured with your OpenAI API Key.
Alternatively use WhisperLocalSpeechToText with a local install of OpenAI Whisper
available from your $PATH or WhisperPath configured in appsettings.json
coffeeshop.netcore.io uses GoogleCloud
As we want to upload and store our Customer voice recordings in managed storage (and be able to later measure their effectiveness) we decided to use Google Cloud since it offers the best value.
It also offers the best latency when using managed storage as when configured to use GoogleCloud Storage, audio recordings only need to upload it once as they can be referenced directly by its Speech-to-text APIs.
To use any of the Google Cloud providers your pc needs to be configured with GoogleCloud Credentials on a project with Speech-to-Text enabled.
Virtual File System
By default CoffeeShop is configured to upload its recordings to the local file system, this can be changed to upload to your preferred Virtual File System provider:
FileSystemVirtualFiles- stores uploads in local file system (default)GoogleCloudVirtualFiles- stores uploads in Google Cloud StorageS3VirtualFiles- stores uploads in AWS S3AzureBlobVirtualFiles- stores uploads in Azure Blob StorageR2VirtualFiles- stores uploads in Cloudflare R2
By configuring VfsProvider in appsettings.json, e.g:
{
"VfsProvider": "GoogleCloudVirtualFiles"
}
Which are configured in Configure.Vfs.cs:
var vfsProvider = appHost.AppSettings.Get<string>("VfsProvider");
if (vfsProvider == nameof(GoogleCloudVirtualFiles))
{
GoogleCloudConfig.AssertValidCredentials();
appHost.VirtualFiles = new GoogleCloudVirtualFiles(
StorageClient.Create(), appHost.Resolve<GoogleCloudConfig>().Bucket!);
}
else if (vfsProvider == nameof(S3VirtualFiles))
{
var aws = appHost.Resolve<AwsConfig>();
appHost.VirtualFiles = new S3VirtualFiles(new AmazonS3Client(
aws.AccessKey,
aws.SecretKey,
aws.ToRegionEndpoint()), aws.Bucket);
}
else if (vfsProvider == nameof(R2VirtualFiles))
{
var r2 = appHost.Resolve<CloudflareConfig>();
appHost.VirtualFiles = new R2VirtualFiles(new AmazonS3Client(
r2.AccessKey,
r2.SecretKey,
new AmazonS3Config {
ServiceURL = r2.ToServiceUrl(),
}), r2.Bucket);
}
else if (vfsProvider == nameof(AzureBlobVirtualFiles))
{
var azure = appHost.Resolve<AzureConfig>();
appHost.VirtualFiles = new AzureBlobVirtualFiles(
azure.ConnectionString, azure.ContainerName);
}
Managed File Uploads
The File Uploads themselves are managed by the Managed File Uploads feature which uses the configuration below to only allows uploading recordings:
- For known Web Audio File Types
- Accepts uploads by anyone
- A maximum size of 1MB
Whose file upload location is derived from when it was uploaded:
Plugins.Add(new FilesUploadFeature(
new UploadLocation("recordings", VirtualFiles, allowExtensions:FileExt.WebAudios, writeAccessRole: RoleNames.AllowAnon,
maxFileBytes: 1024 * 1024,
transformFile: ctx => ConvertAudioToWebM(ctx.File),
resolvePath: ctx => $"/recordings/{ctx.GetDto<IRequireFeature>().Feature}/{ctx.DateSegment}/{DateTime.UtcNow.TimeOfDay.TotalMilliseconds}.{ctx.FileExtension}")
));
Transcribe Audio Recording API
This feature allows the CreateRecording AutoQuery CRUD API
to declaratively support file uploads with the [UploadTo("recordings")] attribute:
public class CreateRecording : ICreateDb<Recording>, IReturn<Recording>
{
[ValidateNotEmpty]
public string Feature { get; set; }
[Input(Type="file"), UploadTo("recordings")]
public string Path { get; set; }
}
Where it will be uploaded to the VirtualFiles provider configured in the recordings file UploadLocation.
As we want the same API to also transcribe the recording, we've implemented a Custom AutoQuery implementation in
GptServices.cs
that after creating the Recording entry with a populated relative Path of where the Audio file was uploaded to,
calls ISpeechToText.TranscribeAsync() to kick off the recording transcription request with the configured Speech-to-text provider.
After it completes its JSON Response is then added to the Recording row and saved to the configured VirtualFiles provider before
being returned in the API Response:
public class GptServices : Service
{
//...
public IAutoQueryDb AutoQuery { get; set; }
public ISpeechToText SpeechToText { get; set; }
public async Task<object> Any(CreateRecording request)
{
var feature = request.Feature.ToLower();
var recording = (Recording)await AutoQuery.CreateAsync(request, Request);
var transcribeStart = DateTime.UtcNow;
await Db.UpdateOnlyAsync(() => new Recording { TranscribeStart = transcribeStart },
where: x => x.Id == recording.Id);
ResponseStatus? responseStatus = null;
try
{
var response = await SpeechToText.TranscribeAsync(request.Path);
var transcribeEnd = DateTime.UtcNow;
await Db.UpdateOnlyAsync(() => new Recording
{
Feature = feature,
Provider = SpeechToText.GetType().Name,
Transcript = response.Transcript,
TranscriptConfidence = response.Confidence,
TranscriptResponse = response.ApiResponse,
TranscribeEnd = transcribeEnd,
TranscribeDurationMs = (int)(transcribeEnd - transcribeStart).TotalMilliseconds,
Error = response.ResponseStatus.ToJson(),
}, where: x => x.Id == recording.Id);
responseStatus = response.ResponseStatus;
}
catch (Exception e)
{
await Db.UpdateOnlyAsync(() => new Recording { Error = e.ToString() },
where: x => x.Id == recording.Id);
responseStatus = e.ToResponseStatus();
}
recording = await Db.SingleByIdAsync<Recording>(recording.Id);
WriteJsonFile($"/speech-to-text/{feature}/{recording.CreatedDate:yyyy/MM/dd}/{recording.CreatedDate.TimeOfDay.TotalMilliseconds}.json",
recording.ToJson());
if (responseStatus != null)
throw new HttpError(responseStatus, HttpStatusCode.BadRequest);
return recording;
}
}
Capturing and Uploading Web Audio Recordings
Now that our Server supports it we can start using this API to upload Audio Recordings. To simplify reuse we've
encapsulated Web Audio API usage behind the AudioRecorder.mjs
class whose start() method starts recording Audio from the Users microphone:
import { AudioRecorder } from "/mjs/AudioRecorder.mjs"
let audioRecorder = new AudioRecorder()
await audioRecorder.start()
Where it captures audio chunks until stop() is called that are then stitched together into a Blob and converted into
a Blob DataURL that's returned within a populated Audio
Media element:
const audio = await audioRecorder.stop()
That supports the HTMLMediaElement API allowing pause and playback of recordings:
audio.play()
audio.pause()
The AudioRecorder also maintains the Blob of its latest recording in its audioBlob field and the MimeType that it was
captured with in audioExt field, which we can use to upload it to the CreateRecording API, which if
successful will return a transcription of the Audio recording:
import { JsonApiClient } from "@servicestack/client"
const client = JsonApiClient.create()
const formData = new FormData()
formData.append('path', audioRecorder.audioBlob, `file.${audioRecorder.audioExt}`)
const api = await client.apiForm(new CreateRecording({feature:'coffeeshop'}),formData)
if (api.succeeded) {
transcript.value = api.response.transcript
}
TypeChat API
Now that we have a transcript of the Customers recording we need to enlist the services of Chat GPT to convert it into an Order request that our App can understand.
ITypeChat
Just as we've abstracted the Transcription Services our App binds to, we also want to abstract the TypeChat provider our App uses so we can easily swap out and evaluate different solutions:
public interface ITypeChat
{
Task<TypeChatResponse> TranslateMessageAsync(TypeChatRequest request,
CancellationToken token = default);
}
Whilst a simple API on the surface, different execution and customizations options are available in the
TypeChatRequest which at a minimum requires the Schema & Prompt to use and the UserMessage to convert:
// Request to process a TypeChat Request
public class TypeChatRequest
{
public TypeChatRequest(string schema, string prompt, string userMessage)
{
Schema = schema;
Prompt = prompt;
UserMessage = userMessage;
}
/// TypeScript Schema
public string Schema { get; set; }
/// TypeChat Prompt
public string Prompt { get; set; }
/// Chat Request
public string UserMessage { get; }
/// Path to node exe (default node in $PATH)
public string? NodePath { get; set; }
/// Timeout to wait for node script to complete (default 120s)
public int NodeProcessTimeoutMs { get; set; } = 120 * 1000;
/// Path to node TypeChat script (default typechat.mjs)
public string? ScriptPath { get; set; }
/// TypeChat Behavior we want to use (Json | Program)
public TypeChatTranslator TypeChatTranslator { get; set; }
/// Path to write TypeScript Schema to (default Temp File)
public string? SchemaPath { get; set; }
/// Which directory to execute the ScriptPath (default CurrentDirectory)
public string? WorkingDirectory { get; set; }
}
IPromptProvider
Whilst App's can use whichever strategy they prefer to generate their TypeScript Schema and Chat GPT Prompt texts,
they can still benefit from implementing the same IPromptProvider interface to improve code reuse which should contain
the App-specific functionality for creating its TypeScript Schema and GPT Prompt from a TypeChatRequest,
which CoffeeShop implements in
CoffeeShopPromptProvider.cs:
// The App Provider to use to generate TypeChat Schema and Prompts
public interface IPromptProvider
{
// Create a TypeChat TypeScript Schema from a TypeChatRequest
Task<string> CreateSchemaAsync(CancellationToken token);
// Create a TypeChat TypeScript Prompt from a User request
Task<string> CreatePromptAsync(string userMessage, CancellationToken token);
}
Semantic Kernel TypeChat Provider
The natural approach for interfacing with OpenAI's ChatGPT API in .NET is to use Microsoft's Semantic Kernel
to call it directly, that CoffeeShop can be configured with by specifying to use KernelTypeChat provider in appsettings.json:
{
"TypeChatProvider": "KernelTypeChat"
}
Which registers the KernelTypeChat in Configure.Gpt.cs
var kernel = Kernel.Builder.WithOpenAIChatCompletionService(
Environment.GetEnvironmentVariable("OPENAI_MODEL") ?? "gpt-3.5-turbo",
Environment.GetEnvironmentVariable("OPENAI_API_KEY")!)
.Build();
services.AddSingleton(kernel);
services.AddSingleton<ITypeChat>(c => new KernelTypeChat(c.Resolve<IKernel>()));
Using Chat GPT to process Natural Language Orders
We now have everything we need to start leveraging Chat GPT to convert our Customers Natural Language requests into Machine readable instructions that our App can understand, guided by TypeChat's TypeScript Schema.
The API to do this needs only a single property to capture the Customer request, that's either provided from a free-text text input or a Voice Input captured by Web Audio:
public class CreateChat : ICreateDb<Chat>, IReturn<Chat>
{
[ValidateNotEmpty]
public string Feature { get; set; }
public string UserMessage { get; set; }
}
That just like CreateRecording is a custom AutoQuery CRUD Service that uses AutoQuery to create the
initial Chat record, that's later updated with the GPT Chat API Response, executed from the configured
ITypeChat provider:
public class GptServices : Service
{
//...
public IAutoQueryDb AutoQuery { get; set; }
public IPromptProvider PromptProvider { get; set; }
public ITypeChat TypeChatProvider { get; set; }
public async Task<object> Any(CreateChat request)
{
var feature = request.Feature.ToLower();
var promptProvider = PromptFactory.Get(feature);
var chat = (Chat)await AutoQuery.CreateAsync(request, Request);
var chatStart = DateTime.UtcNow;
await Db.UpdateOnlyAsync(() => new Chat { ChatStart = chatStart },
where: x => x.Id == chat.Id);
ResponseStatus? responseStatus = null;
try
{
var schema = await promptProvider.CreateSchemaAsync();
var prompt = await promptProvider.CreatePromptAsync(request.UserMessage);
var typeChatRequest = CreateTypeChatRequest(feature, schema, prompt, request.UserMessage);
var response = await TypeChat.TranslateMessageAsync(typeChatRequest);
var chatEnd = DateTime.UtcNow;
await Db.UpdateOnlyAsync(() => new Chat
{
Request = request.UserMessage,
Feature = feature,
Provider = TypeChat.GetType().Name,
Schema = schema,
Prompt = prompt,
ChatResponse = response.Result,
ChatEnd = chatEnd,
ChatDurationMs = (int)(chatEnd - chatStart).TotalMilliseconds,
Error = response.ResponseStatus.ToJson(),
}, where: x => x.Id == chat.Id);
responseStatus = response.ResponseStatus;
}
catch (Exception e)
{
await Db.UpdateOnlyAsync(() => new Chat { Error = e.ToString() },
where: x => x.Id == chat.Id);
responseStatus = e.ToResponseStatus();
}
chat = await Db.SingleByIdAsync<Chat>(chat.Id);
WriteJsonFile($"/chat/{feature}/{chat.CreatedDate:yyyy/MM/dd}/{chat.CreatedDate.TimeOfDay.TotalMilliseconds}.json", chat.ToJson());
if (responseStatus != null)
throw new HttpError(responseStatus, HttpStatusCode.BadRequest);
return chat;
}
}
The API then returns Chat GPTs JSON Response directly to the client:
apiChat.value = await client.api(new CreateChat({
feature: 'coffeeshop',
userMessage: request.toLowerCase()
}))
if (apiChat.value.response) {
processChatItems(JSON.parse(apiChat.value.response.chatResponse).items)
} else if (apiChat.value.error) {
apiProcessed.value = apiChat.value
}
That's in the structure of the TypeScript Schema's array of Cart LineItem's which are matched against the
products and available customizations from the App's database before being added to the user's cart in the
processChatItems(items) function.
Trying it Out
Now that all the pieces are connected together, we can finally try it out! Hit the Record Icon to start the microphone recording to capture CoffeeShop Orders via Voice Input.
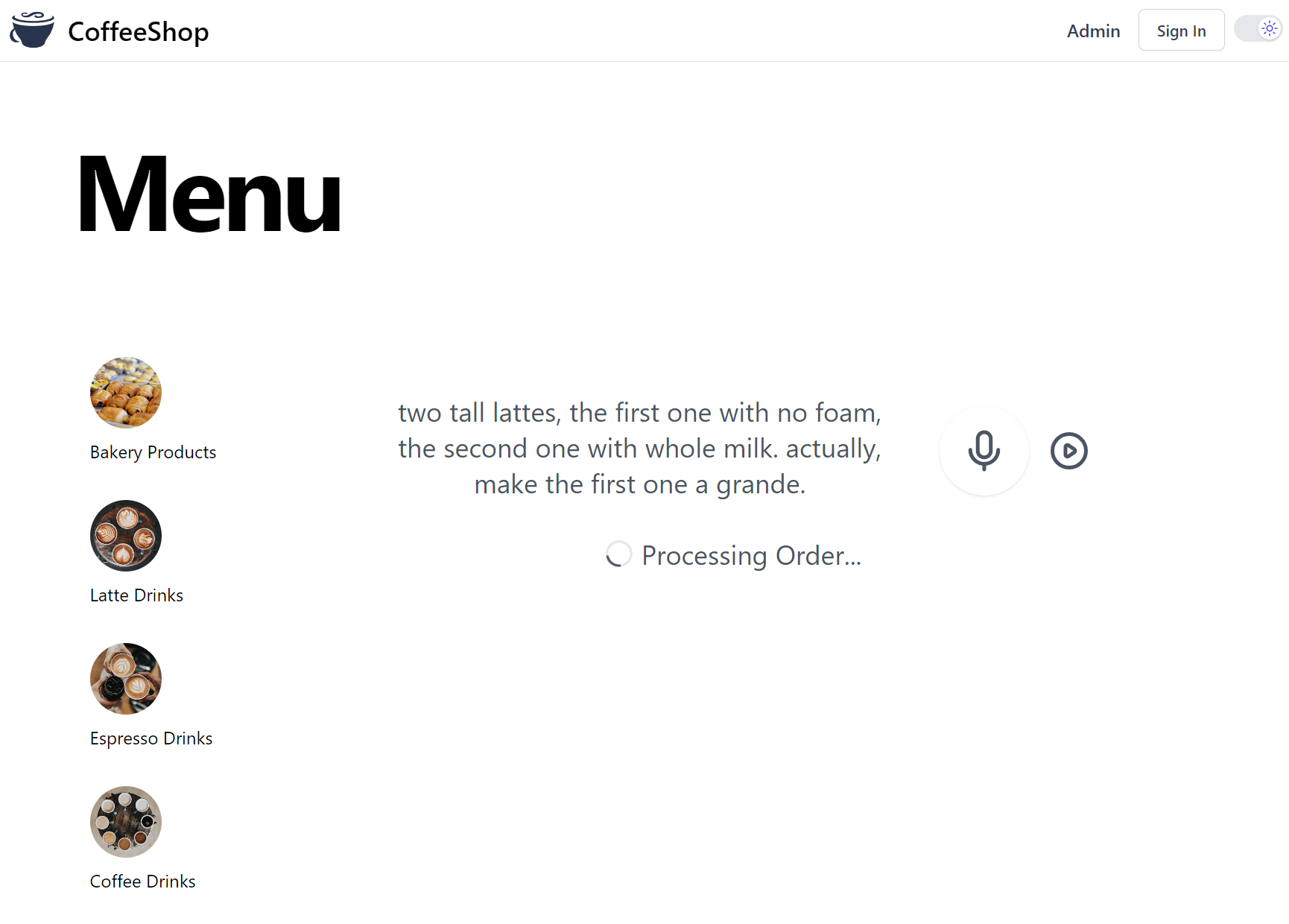
Let's try a Natural Language Customer Order whose free-text input would be notoriously difficult to parse with traditional programming methods:
two tall lattes, the first one with no foam, the second one with whole milk. actually, make the first one a grande.
After the configured ISpeechToText provider has finished transcribing the uploaded Voice Recording it will display
the transcribed text whilst the request is being processed by Chat GPT:
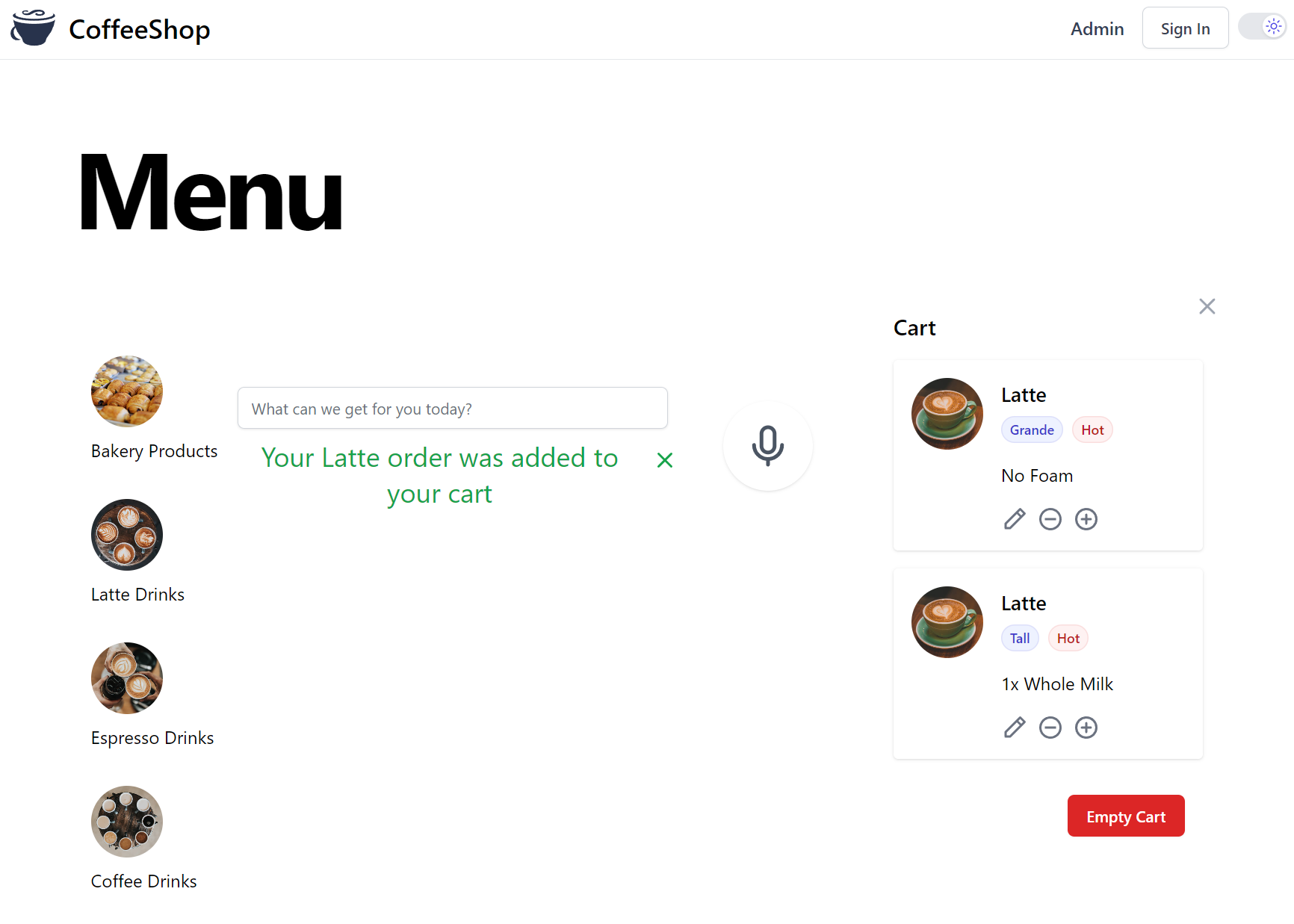
Then if all was successful we should see the Customer Order appear in the Customer's Cart, as if by magic!
Semantic Kernel Effectiveness
Most times you'll get the same desirable results when using Semantic Kernel to call Chat GPT from C# compared with calling Chat GPT through node TypeChat as both are sending the same prompt to Chat GPT.
Where they begin to differ is how they deal with invalid and undesirable responses from vague or problematic requests.
Lets take a look at an order from TypeChat's input's that Chat GPT had issues with:
i wanna latte macchiato with vanilla
That our Semantic Kernel Request translates into a reasonable Cart Item order:
{
"items": [
{
"type": "lineitem",
"product": {
"type": "LatteDrinks",
"name": "latte macchiato",
"options": [
{
"type": "Syrups",
"name": "vanilla"
}
]
},
"quantity": 1
}
]
}
The problem being "vanilla" is close, but it's not an exact match for a Syrup on offer, so our order only gets partially filled:
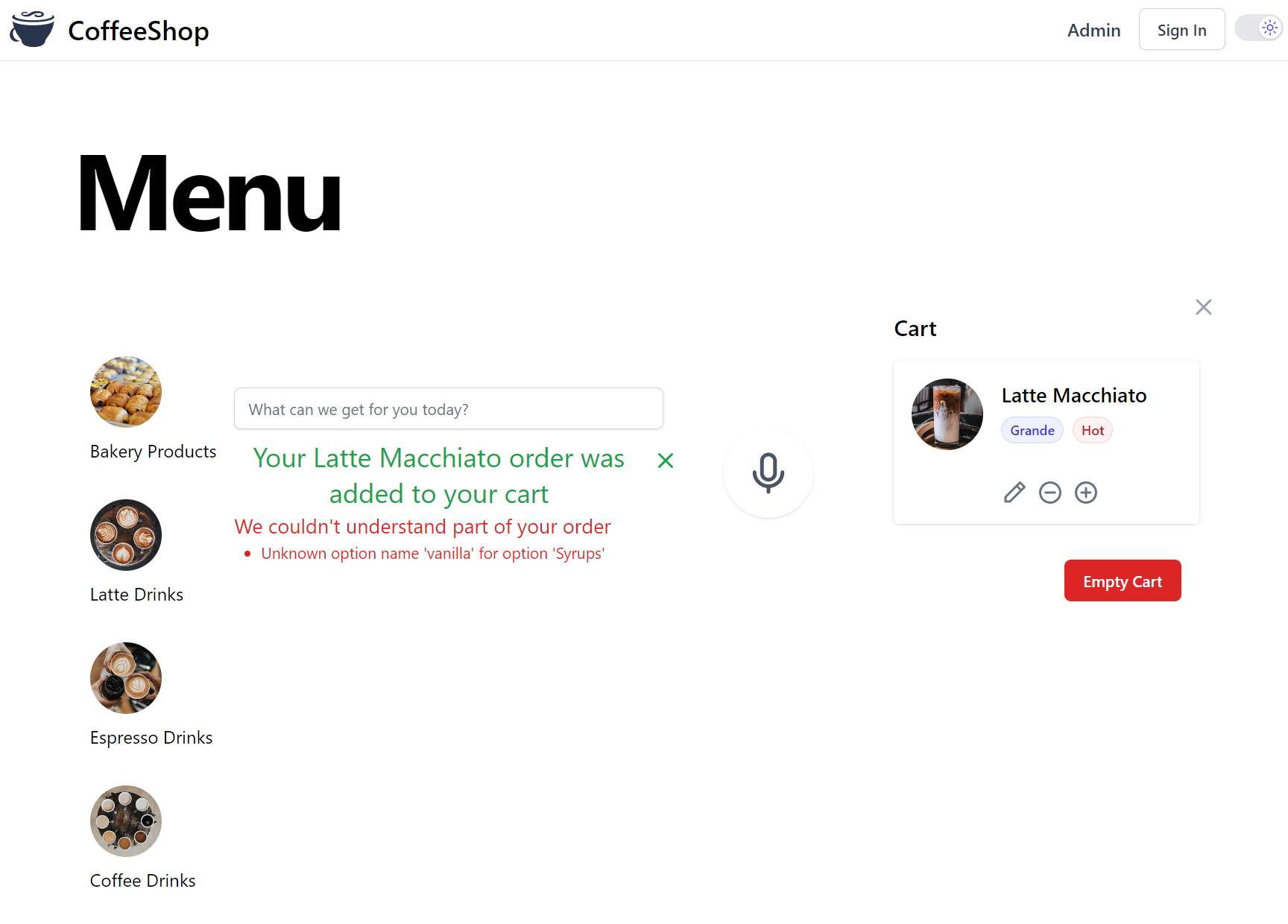
TypeChat's Invalid Response Handling
So how does TypeChat fair when handling the same problematic prompt?
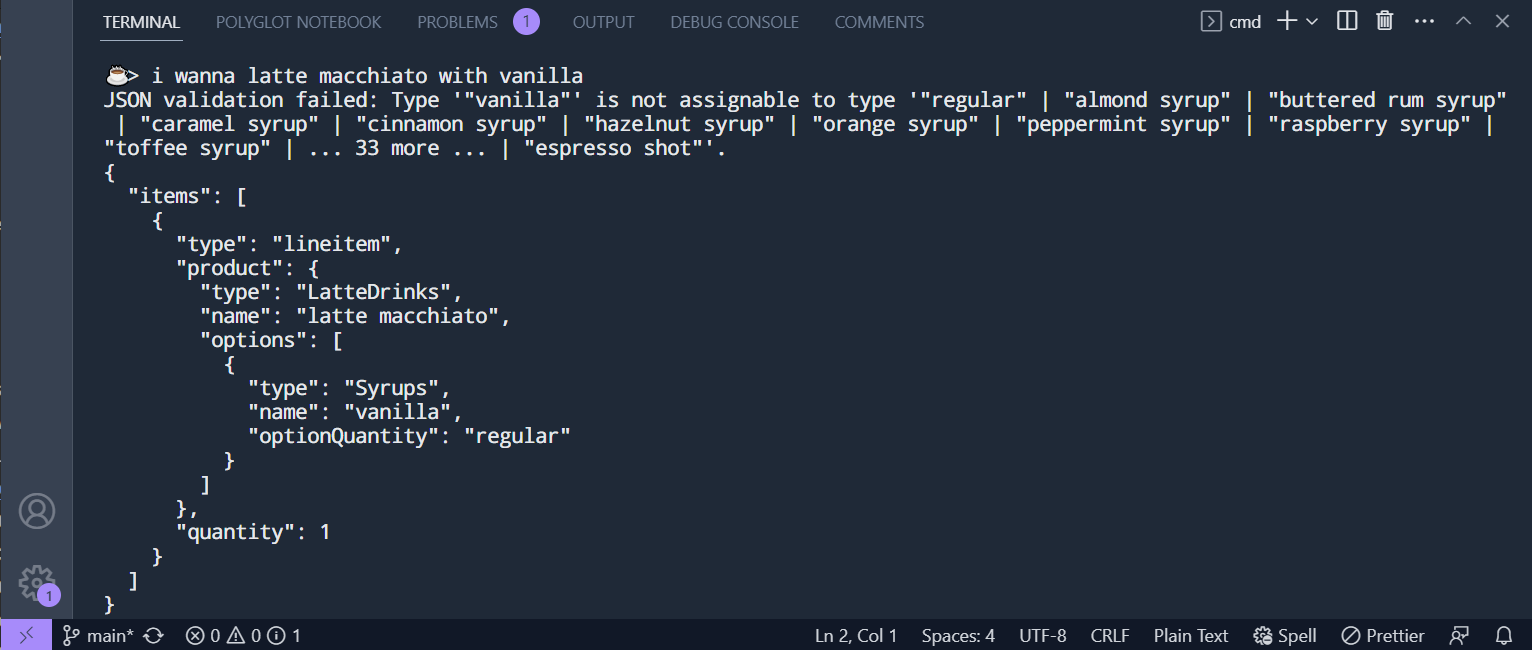
It expectedly fails in the same way, but as it's able to validate JSON responses against the TypeScript's schema it knows and can report back where the failure occurs through the TypeScript's compiler schema validation errors.
TypeChat's Auto Retry of Failed Requests
Interestingly before reporting back the schema validation error TypeChat had transparently sent a retry request back to Chat GPT with the original prompt with some additional context to help guide GPT into returning a valid response where it includes the invalid response it had received, an error message to say why it was invalid and the Schema Validation Error:
//...
{
"items": [
{
"type": "lineitem",
"product": {
"type": "LatteDrinks",
"name": "latte macchiato",
"options": [
{
"type": "Syrups",
"name": "vanilla"
}
]
},
"quantity": 1
}
]
}
The JSON object is invalid for the following reason:
"""
Type '"vanilla"' is not assignable to type '"butter" | "strawberry jam" | "cream cheese" | "regular" | "warmed" | "cut in half" | "whole milk" | "two percent milk" | "nonfat milk" | "coconut milk" | "soy milk" | "almond milk" | ... 42 more ... | "heavy cream"'.
"""
The following is a revised JSON object:
Unfortunately in this case the schema validation error is incomplete and doesn't include the valid values for
the Syrups type, so ChatGPT 3.5 never gets it right.
Custom Validation with C# Semantic Kernel
The benefit of TypeScript Schema validation errors are that they require little effort since they're automatically generated by TypeScript's compiler. Since TypeChat isn't able to resolve the issue in this case, can we do better?
As we already need to perform our own validation to match GPT's Cart response back to our database products, we
can construct our own auto-correcting prompt by specifying what was wrong and repeating the definition of the failed
Syrups type, e.g:
//...
JSON validation failed: 'vanilla' is not a valid name for the type: Syrups
export interface Syrups {
type: 'Syrups';
name: 'almond syrup' | 'buttered rum syrup' | 'caramel syrup' | 'cinnamon syrup' | 'hazelnut syrup' |
'orange syrup' | 'peppermint syrup' | 'raspberry syrup' | 'toffee syrup' | 'vanilla syrup';
optionQuantity?: OptionQuantity;
}
Lo and behold we get what we're after, an expected valid response with the correct "vanilla syrup" value:
{
"items": [
{
"type": "lineitem",
"product": {
"type": "LatteDrinks",
"name": "latte macchiato",
"options": [
{
"type": "Syrups",
"name": "vanilla syrup"
}
]
},
"quantity": 1
}
]
}
This goes to show that interfacing with ChatGPT in C# with Semantic Kernel is a viable solution that whilst requires more bespoke logic and manual validation, can produce a more effective response than what's possible with TypeChat's schema validation errors.
If you need to maintain few interfaces with ChatGPT, building your solution all in .NET might be the best option, but if you need to generate and maintain multiple schemas then using a generic library with automated retries like TypeChat utilizing TypeScript Schema validation errors is likely preferred.
TypeChat with ChatGPT 4
As we're not able to achieve a successful response from this problematic request from GPT-3.5, would ChatGPT 4 fair any better?
Lets try by setting the OPENAI_MODEL Environment Variable to gpt-4 in your shell:
set OPENAI_MODEL=gpt-4
Then retry the same request:
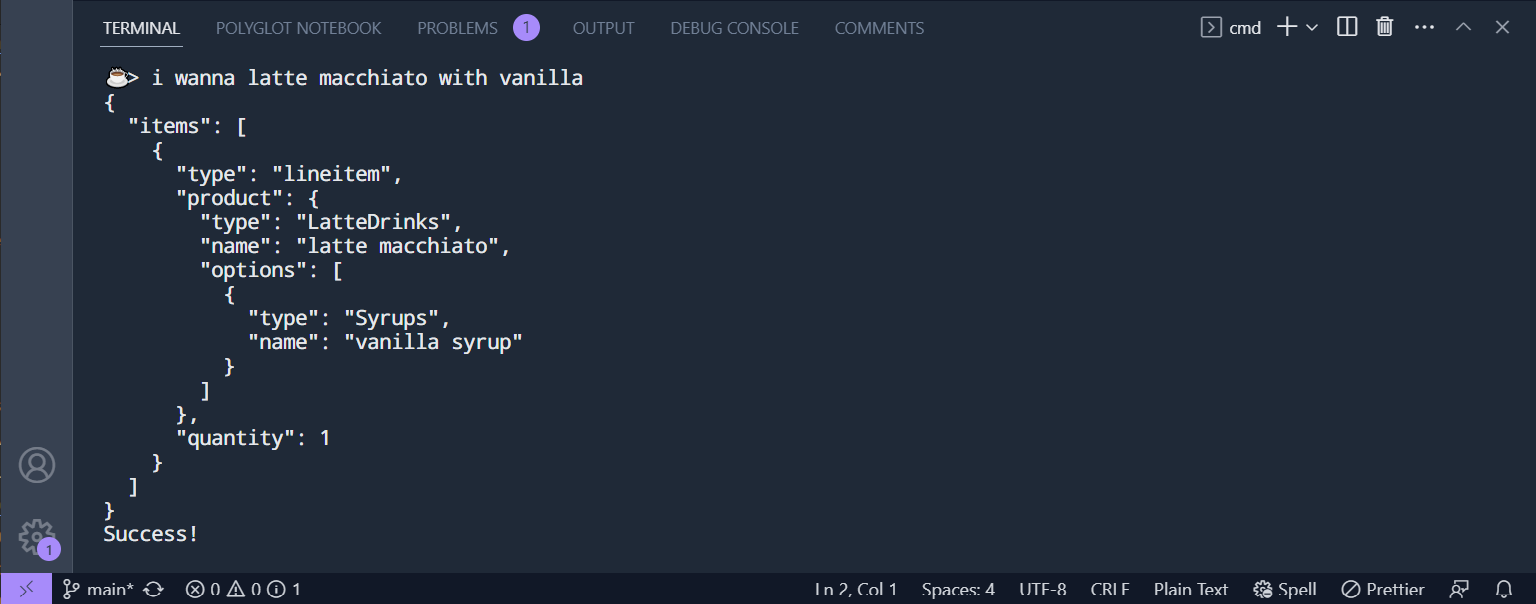
Success! GPT-4 didn't even need the retry and gets it right in one-shot on its first try.
So the easiest way to improve the success rate of your TypeChat GPT solutions is to switch to GPT-4, or for a more cost effective approach you can start with GPT-3.5 than retry failed requests with GPT-4.
Node TypeChat Provider
As TypeChat uses typescript we'll need to call out to the node executable in order to be able to use it from our .NET App.
To configure our App to talk to ChatGPT API via TypeChat we need to specify to use NodeTypeChat provider in appsettings.json:
{
"TypeChatProvider": "NodeTypeChat"
}
Which will configure to use the NodeTypeChat in Configure.Gpt.cs
services.AddSingleton<ITypeChat>(c => new NodeTypeChat());
It works by executing an external process that invokes our custom
typechat.mjs wrapper around TypeChat's
functionality to invoke it and return any error responses in a structured ResponseStatus format that our .NET App
can understand, which you can also invoke manually from the command line with:
node typechat.mjs json gpt\coffeeshop\schema.ts "i wanna latte macchiato with vanilla"
Lets test this out this with an OPENAI_MODEL=gpt-4 Environment Variable so we can see the above problematic prompt
working in our App:
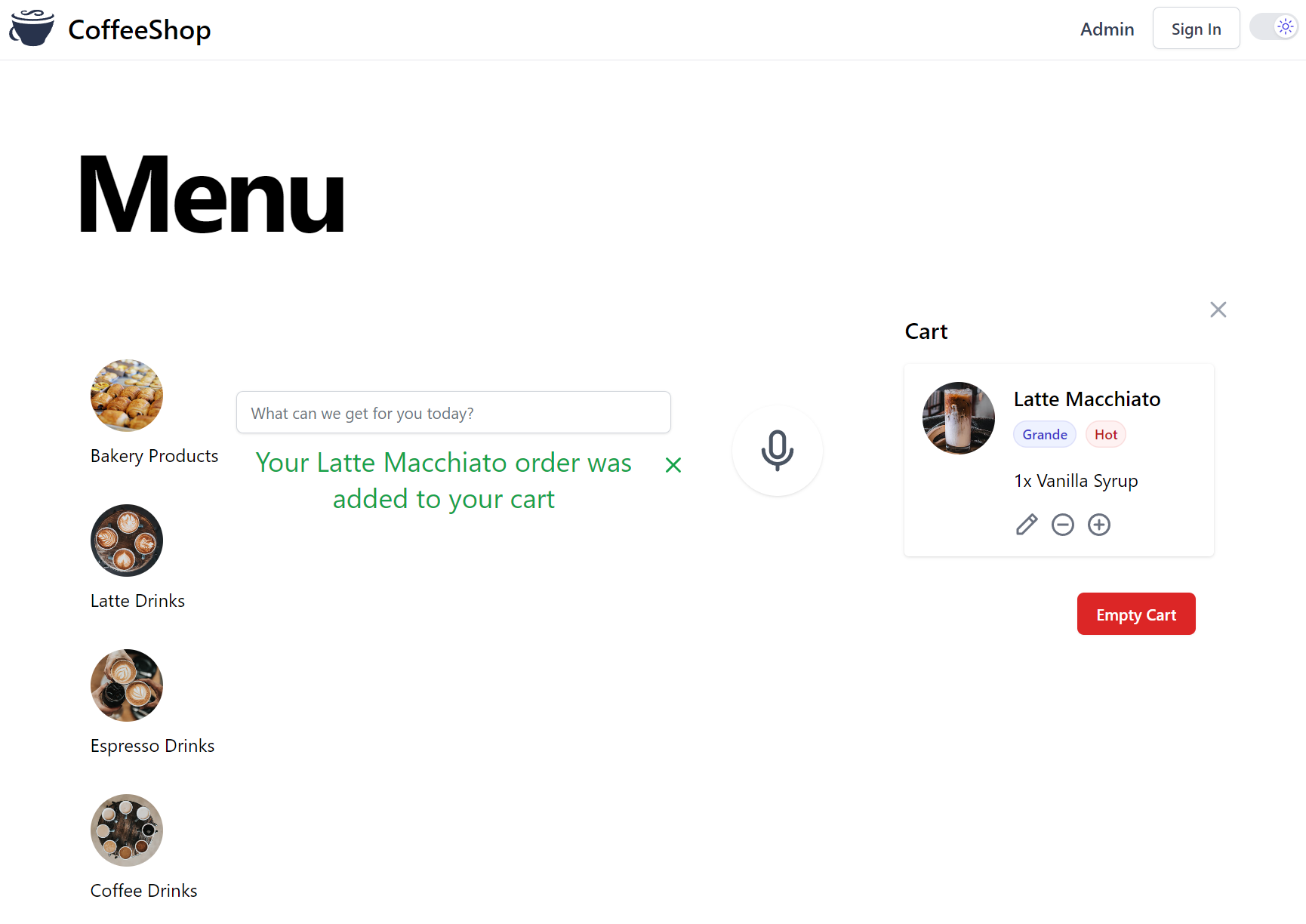
With everything connected and working together, try node's TypeChat out by ordering something from the CoffeeShop Menu or try out some of TypeChat's input.txt examples for inspiration.
Try Alternative Providers
Feel free to try and evaluate different providers to measure how well each performs, if you prefer a managed cloud option switch to use GoogleCloud to store voice recordings and transcribe audio by configuring appsettings.json with:
{
"VfsProvider": "GoogleCloudVirtualFiles",
"SpeechProvider": "GoogleCloudSpeechToText"
}
Using GoogleCloud Services requires your workstation to be configured with GoogleCloud Credentials.
A nice feature from using Cloud Services is the built-in tooling in IDEs like JetBrains Big Data Tools where you can inspect new Recordings and ChatGPT JSON responses from within your IDE, instead of SSH'ing into remote servers to inspect local volumes:
Workaround for Safari
CoffeeShop worked great in all modern browsers we tested on in Windows including: Chrome, Edge, Firefox and Vivaldi but unfortunately failed in Safari which seemed strange since we're using WebM:
the open, royalty-free, media file format designed for the web!
So much for "open formats", guess we'll have to switch to the format that all browsers support. This information isn't readily available so I used this little script to detect which popular formats are supported in each browser:
const containers = ['webm', 'ogg', 'mp4', 'x-matroska', '3gpp', '3gpp2',
'3gp2', 'quicktime', 'mpeg', 'aac', 'flac', 'wav']
const codecs = ['vp9', 'vp8', 'avc1', 'av1', 'h265', 'h.265', 'h264',
'h.264', 'opus', 'pcm', 'aac', 'mpeg', 'mp4a'];
const supportedAudios = containers.map(format => `audio/${format}`)
.filter(mimeType => MediaRecorder.isTypeSupported(mimeType))
const supportedAudioCodecs = supportedAudios.flatMap(audio =>
codecs.map(codec => `${audio};codecs=${codec}`))
.filter(mimeType => MediaRecorder.isTypeSupported(mimeType))
console.log('Supported Audio formats:', supportedAudios)
console.log('Supported Audio codecs:', supportedAudioCodecs)
Windows
All Chrome and Blink-based browsers inc. Edge and Vivaldi reported the same results:
Supported Audio formats: ['audio/webm']
Supported Audio codecs: ['audio/webm;codecs=opus', 'audio/webm;codecs=pcm']
Whilst Firefox reported:
Supported Audio formats: ["audio/webm", "audio/ogg"]
Supported Audio codecs: ["audio/webm;codecs=opus", "audio/ogg;codecs=opus"]
Things aren't looking good, we have exactly one shared Audio Format and Codec supported by all modern browsers on Windows.
macOS
What does Safari say it supports?
Supported Audio formats: ["audio/mp4"]
Supported Audio codecs: ["audio/mp4;codecs=avc1", "audio/mp4;codecs=mp4a"]
That's unfortunate, The only Audio format Safari supports isn't supported by any other browser, even worse it's not an audio encoding that Google Speech-to-text supports.
This means if we want to be able to serve Customers with shiny iPhone's we're going to need to convert it into a format
that the Speech-to-text APIs accepts, the logical choice being to use the same format that we're capturing from other
browsers natively, i.e. audio/webm.
ffmpeg
Our first attempt to do this in .NET with NAudio failed on macOS since it relied on Windows APIs to perform the conversion.
Luckily this is pretty easy to do with the amazingly versatile ffmpeg - that can be installed on macOS with Homebrew:
brew install ffmpeg
Whilst CoffeeShop's Ubuntu 22.04 Dockerfile it uses to deploy to Linux installs it with:
RUN apt-get clean && apt-get update && apt-get upgrade -y \
&& apt-get install -y --no-install-recommends curl gnupg ffmpeg
Converting Uploaded Files
We now need to integrate this conversion into our workflow. As we're using
Managed Files Uploads to handle our uploads, the best place to
add support for it is in transformFile where you can intercept the file upload and transform it to a more suitable
upload for your App to work with, by configuring the UploadLocation in
Configure.AppHost.cs:
Plugins.Add(new FilesUploadFeature(
new UploadLocation("recordings", VirtualFiles, allowExtensions:FileExt.WebAudios, writeAccessRole: RoleNames.AllowAnon,
maxFileBytes: 1024 * 1024,
transformFile: ctx => ConvertAudioToWebM(ctx.File),
resolvePath: ctx => $"/recordings/{ctx.DateSegment}/{DateTime.UtcNow.TimeOfDay.TotalMilliseconds}.{ctx.FileExtension}")
));
Where the ConvertAudioToWebM handles converting Safari's .mp4 Audio recordings into .webm format by executing
the external ffmpeg process, the converted file is then returned in a new HttpFile referencing the new .webm Stream contents:
public async Task<IHttpFile?> ConvertAudioToWebM(IHttpFile file)
{
if (!file.FileName.EndsWith("mp4"))
return file;
var ffmpegPath = ProcessUtils.FindExePath("ffmpeg")
?? throw new Exception("Could not resolve path to ffmpeg");
var now = DateTime.UtcNow;
var time = $"{now:yyyy-M-d_s.fff}";
var tmpDir = Environment.CurrentDirectory.CombineWith("App_Data/tmp").AssertDir();
var tmpMp4 = tmpDir.CombineWith($"{time}.mp4");
await using (File.Create(tmpMp4)) {}
var tmpWebm = tmpDir.CombineWith($"{time}.webm");
var msMp4 = await file.InputStream.CopyToNewMemoryStreamAsync();
await using (var fsMp4 = File.OpenWrite(tmpMp4))
{
await msMp4.WriteToAsync(fsMp4);
}
await ProcessUtils.RunShellAsync($"{ffmpegPath} -i {tmpMp4} {tmpWebm}");
File.Delete(tmpMp4);
HttpFile? to = null;
await using (var fsWebm = File.OpenRead(tmpWebm))
{
to = new HttpFile(file) {
FileName = file.FileName.WithoutExtension() + ".webm",
InputStream = await fsWebm.CopyToNewMemoryStreamAsync()
};
}
File.Delete(tmpWebm);
return to;
}
In the terminal this simply done by specifying the file.mp4 input file and the output file extension and format you want it converted to:
ffmpeg -i file.mp4 file.webm
With this finishing touch CoffeeShop is now accepting Customer Orders from all modern browsers in all major Operating Systems at:
https://coffeeshop.netcore.io
Local OpenAI Whisper
CoffeeShop also serves as nice real-world example we can use to evaluate the effectiveness of different GPT models, which has been surprisingly effortless on Apple Silicon whose great specs and popularity amongst developers means a lot of the new GPT projects are well supported on my new M2 Macbook Air.
As we already have ffmpeg installed, installing OpenAI's Whisper can be done with:
pip install -U openai-whisper
Where you'll then be able to transcribe Audio recordings that's as easy as specifying the recording you want a transcription of:
whisper recording.webm
Usage Notes
- The
--languageflag helps speed up transcriptions by avoiding needing to run auto language detection - By default whisper will generate its transcription results in all supported
.txt,.json,.tsv,.srtand.vttformats- you can limit to just the format you want it in with
--output_format, e.g. usetxtif you're just interested in the transcribed text
- you can limit to just the format you want it in with
- The default install also had FP16 and Numba Deprecation warnings
All these issues were resolved by using the modified prompt:
export PYTHONWARNINGS="ignore"
whisper --language=en --fp16 False --output_format txt recording.webm
Which should now generate a clean output containing the recordings transcribed text, that's also written to recording.txt:
[00:00.000 --> 00:02.000] A latte, please.
Which took 9 seconds to transcribe on my M2 Macbook Air, a fair bit longer than the 1-2 seconds it takes to upload and transcribe recordings to Google Cloud, but still within acceptable response times for real-time transcriptions.
Switch to local OpenAI Whisper
You can evaluate how well local whisper performs for transcribing CoffeeShop recordings in appsettings.json:
{
"SpeechProvider": "WhisperLocalSpeechToText"
}
Which configures Configure.Speech.cs
to use WhisperLocalSpeechToText:
services.AddSingleton<ISpeechToText>(c => new WhisperLocalSpeechToText {
WhisperPath = c.Resolve<AppConfig>().WhisperPath ?? ProcessUtils.FindExePath("whisper"),
TimeoutMs = c.Resolve<AppConfig>().NodeProcessTimeoutMs,
});
Running LLMs Locally
Being able to run OpenAI's Whisper locally gives our App the option for removing
an external API and infrastructure dependency, will it also be possible to run LLM locally to remove our ChatGPT dependency?
Thanks to tools like llama.cpp we're able to run popular Open Source LLMs from our laptops. An easy way to easily download and evaluate different LLMs is using the llm Python utility that can be installed with:
pip install llm
That you can use to install the llama.cpp plugin with:
llm install llm-llama-cpp
Then use that it to download the popular Llama2 7B model with:
llm llama-cpp download-model \
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q8_0.bin \
--alias llama2-chat --alias l2c --llama2-chat
Which lets us ask our local LLama2 model what we want, a great list used to measure the effectiveness of different LLMs can be found at benchmarks.llmonitor.com:
llm -m l2c 'Argue for and against the use of kubernetes in the style of a haiku.'
Which our Llama2 took 64.51s to responded with:
Sure, I can provide a haiku argument for and against the use of Kubernetes:
**For Kubernetes:**
Containerized world
Efficiently orchestrated bliss
Apps swim with ease
Kubernetes reigns
Managing pods with grace
Smooth sailing ahead
**Against Kubernetes:**
Overcomplicated sea
Cluttered with APIs and tools
Tainted by complexity
Kubernetes, alas
Forcing us to conform
To its rigid ways
The response is impressive, unfortunately taking over 1 minute to execute wasn't.
Whilst we're here lets see how viable the Open Source models are for evaluating our natural language CoffeeShop orders, which we can do with:
curl --get --data-urlencode "userMessage=i'd like a latte that's it" \
https://coffeeshop.netcore.io/coffeeshop/prompt | llm -m l2c
tip
Or use https://localhost:5001/coffeeshop/prompt to use a local App prompt
Which we're happy to report returns a valid JSON prompt our App can process:
{
"items": [
{
"type": "lineitem",
"product": {
"type": "LatteDrinks",
"name": "latte",
"temperature": "hot",
"size": "grande"
},
"quantity": 1
}
]
}
Whilst Llama2 7B isn't nearly as capable or accurate as ChatGPT, it demonstrates potential for Open Source LLMs to eventually become a viable option for being able to add support for natural language requests in our Apps.
Unfortunately the 105s time it took to execute makes it unsuitable for handling any real-time tasks, when running on laptop hardware at least with only a 10-core GPU and 24GB RAM with 100GB/s memory bandwidth.
But the top-line specs of PC's equipped with high-end Nvidia GPUs or Apple Silicon's Mac Studio Ultra's impressive 76-core GPU with 192GB RAM at 800GB/s memory bandwidth should mean we'll be able to run our AI workloads on consumer hardware in the not too distant future.
Local AI Workflows
Whilst running all our App's AI requirements from a laptop may not be feasible just yet, we're still able to execute some cool AI workflows that's only been possible to do from our laptop's until very recently.
For example, this shell command:
- uses ffmpeg to capture 5 seconds of our voice recording
- uses whisper to transcribe our recording to text
- uses CoffeeShop Prompt API to create a TypeChat Request from our text order
- uses llm to execute our App's TypeChat prompt with our local Llama2 7B LLM
ffmpeg -f avfoundation -i ":1" -t 5 order.mp3 \
&& whisper --language=en --fp16 False --output_format txt order.mp3 \
&& curl --get --data-urlencode "userMessage=$(cat order.txt)" \
https://coffeeshop.netcore.io/coffeeshop/prompt | llm -m l2c
If all stars have aligned you should get a machine readable JSON response the CoffeeShop can process to turn your voice recording into a Cart order:
{
"items": [
{
"type": "lineitem",
"product": {
"type": "LatteDrinks",
"name": "latte",
"temperature": "hot",
"size": "grande"
},
"quantity": 1
}
]
}
New .NET TypeChat Examples Soon
Watch this space or join our Newsletter (max 1 email / 2-3 months) to find out when new .NET implementations for TypeChat's different GPT examples become available.



