Real-time search with Typesense
We have recently migrated the ServiceStack Docs website from using Jekyll for static site generation (SSG) to using VitePress which enables us to use Vite with Vue 3 components and have an insanely fast hot reload while we update our documentation.
VitePress is very well suited to documentation sites, and it is one of the primary use cases for VitePress at the time of writing. The default theme even has optional integration with Algolia DocSearch. However, the Algolia DocSeach product didn’t seem to offer the service for commercial products even as a paid service and their per request pricing model made it harder to determine what our costs would be in the long run for using their search service for our documentation.
We found Typesense as an appealing alternative which offers simple cost-effective cloud hosting but even better, they also have an easy to use open source option for self-hosting or evaluation. We were so pleased with its effortless adoption, simplicity-focus and end-user UX that it quickly became our preferred way to navigate our docs. So that more people can find out about Typesense’s amazing OSS Search product we’ve documented our approach used for creating and deploying an index of our site using GitHub Actions.
Documentation search is a common use case which Typesense caters for with their typesense-docsearch-scraper. This is a utility designed to easily scrape a documentation site and post the results to a Typesense server to create a fast searchable index.
Self hosting option
Since we already have several AWS instances hosting our example applications, we opted to start with a self hosting on AWS Elastic Container Service (ECS) since Typesense is already packaged into an easy to use Docker image.
Trying it locally, we used the following commands to spin up a local Typesense server ready to scrape out docs site.
mkdir /tmp/typesense-data
docker run -p 8108:8108 -v/tmp/data:/data typesense/typesense:0.21.0 \
--data-dir /data --api-key=<temp-admin-api-key> --enable-cors
To check that the server is running, we can open a browser at /health and we get back 200 OK with ok: true.
The Typesense server has a REST API which can be used to manage the indexes you create. The cloud offering comes with a web dashboard to manage your data which is a definite advantage over the self hosting, but for now we were still trying it out.
Populating our index
Now that our local server is running, we can scrape our docs site using the typesense-docsearch-scraper. This needs some configuration since the scraper needs to know:
- Where is the Typesense server.
- How to authenticate with the Typesense server.
- Where is the docs website.
- Rules for the scraper to follow extracting information from the docs website.
These pieces of configuration come from 2 sources. A .env file related to the Typesense server information and a .json file related to what site will be getting scraped.
With our Typesense running locally on port 8108, we configure the .env file with the following information.
TYPESENSE_API_KEY=${TYPESENSE_API_KEY}
TYPESENSE_HOST=localhost
TYPESENSE_PORT=8108
TYPESENSE_PROTOCOL=http
Next, we have the .json config for the scraper. The typesense-docsearch-scraper gives an example of this config in their repository for what this config should look like.
Altering the default selectors to match the HTML for our docs site, we ended up with a configuration that looked like this.
{
"index_name": "typesense_docs",
"allowed_domains": ["docs.servicestack.net"],
"start_urls": [
{
"url": "https://docs.servicestack.net/"
}
],
"selectors": {
"default": {
"lvl0": ".page h1",
"lvl1": ".content h2",
"lvl2": ".content h3",
"lvl3": ".content h4",
"lvl4": ".content h5",
"text": ".content p, .content ul li, .content table tbody tr"
}
},
"scrape_start_urls": false,
"strip_chars": " .,;:#"
}
Now we have both the configuration files ready to use, we can run the scraper itself. The scraper is also available using the docker image typesense/docsearch-scraper and we can pass our configuration to this process using the following command.
docker run -it --env-file typesense-scraper.env \
-e "CONFIG=$(cat typesense-scraper-config.json | jq -r tostring)" \
typesense/docsearch-scraper
Here we are using -i so we can reference our local --env-file and use cat and jq to populate the CONFIG environment variable using our .json config file.
Docker networking
Here we run into a bit of a issue, since the scraper itself is running in Docker via WSL, localhost isn’t resolving to our host machine to find the Typesense server also running in Docker.
Instead we need to point the scraper to the Typesense server using the Docker local IP address space of 172.17.0.0/16 for it to resolve without additional configuration.
We can see in the output of the Typesense server that it is running using 172.17.0.2. We can swap the localhost with this IP address and communication is flowing.
DEBUG:typesense.api_call:Making post /collections/typesense_docs_1635392168/documents/import
DEBUG:typesense.api_call:Try 1 to node 172.17.0.2:8108 -- healthy? True
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): 172.17.0.2:8108
DEBUG:urllib3.connectionpool:http://172.17.0.2:8108 "POST /collections/typesense_docs_1635392168/documents/import HTTP/1.1" 200 None
DEBUG:typesense.api_call:172.17.0.2:8108 is healthy. Status code: 200
> DocSearch: https://docs.servicestack.net/azure 22 records)
DEBUG:typesense.api_call:Making post /collections/typesense_docs_1635392168/documents/import
DEBUG:typesense.api_call:Try 1 to node 172.17.0.2:8108 -- healthy? True
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): 172.17.0.2:8108
DEBUG:urllib3.connectionpool:http://172.17.0.2:8108 "POST /collections/typesense_docs_1635392168/documents/import HTTP/1.1" 200 None
The scraper crawls the docs site following all the links in the same domain to get a full picture of all the content of our docs site. This takes a minute or so, and in the end we can see in the Typesense sever output that we now have “committed_index: 443”.
_index: 443, applying_index: 0, pending_index: 0, disk_index: 443, pending_queue_size: 0, local_sequence: 44671
I20211028 03:39:40.402626 328 raft_server.h:58] Peer refresh succeeded!
Searching content
So now we have a Typesense server with an index full of content, we want to be able to search it on our docs site.
Querying our index using straight cURL, we can see the query itself only needs to known 3 pieces of information at a minimum.
- Collection name, eg
typesense_docs - Query term,
?q=test - What to query,
&query_by=content
curl -H 'x-typesense-api-key: <apikey>' \
'http://localhost:8108/collections/typesense_docs/documents/search?q=test&query_by=content'
The collection name and query_by come from how our scraper were configured. The scraper was posting data to the
typesense_docs collection and populating various fields, eg content.
Which as it returns JSON can be easily queried in JavaScript using fetch:
fetch('http://localhost:8108/collections/typesense_docs/documents/search?q='
+ encodeURIComponent(query) + '&query_by=content', {
headers: {
// Search only API key for Typesense.
'x-typesense-api-key': 'TYPESENSE_SEARCH_ONLY_API_KEY'
}
})
In the above we have also used a different name for the API key token, this is important since the --api-key specified to the running Typesense server is the admin API key. You don’t want to expose this to a browser client since they will have the ability to create,update and delete your collections or documents.
Instead we want to generate a “Search only” API key that is safe to share on a browser client. This can be done using the Admin API key and the following REST API call to the Typesense server.
curl 'http://localhost:8108/keys' -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
-H 'Content-Type: application/json' \
-d '{"description": "Search only","actions": ["documents:search"],"collections":["*"]}'
Now we can share this generated key safely to be used with any of our browser clients.
Keeping the index updated
Another problem that becomes apparent is that subsequent usages of the scraper increases the size of our index since it currently doesn’t detect and update existing documents. It wasn’t clear if this is possible to configure or manage from the current scraper (ideally by using URL paths as the unique identifier), so we needed a way to achieve the following goals.
- Update the search index automatically soon after docs have been changed
- Don’t let the index grow too big causing manual intervention
- Have high uptime for our search so users can always search our docs
Typesense server itself performs extremely well, so a full update from the scraper doesn’t generate an amount of load that is of much a concern. This is also partly because the scraper seems to be sequentially crawling pages so it can only generate so many updates on single thread. However, every additional scrape will use additional disk space and memory for the running server causing us to periodically reset the index and repopulate, causing downtime.
One option is to switch to a new collection everytime we update the docs sites and delete the old collection. This requires additional orchestration between client and the server, and to avoid down time the following order of operations would be needed.
- Docs are updated
- Publish updated docs
- Create new collection, store new name + old name
- Scrape updated docs
- Update client with new collection name
- Delete old collection
This dance would require multiple commits/actions in GitHub (we use GitHub Actions), and also be time sensitive since it will be non-deterministic as to how long it will take to scrape, update, and deploy our changes.
Additional operational burden is something we want to avoid since it an on going cost on developer time that would otherwise be spent improving ServiceStack offerings for our customers.
Read-only Docker container
Something to keep in mind when making architecture decisions is looking at the specifics of what is involved when it comes to the flow of data of your systems.
You can ask yourself questions like:
- What data is updated
- When/How often is data updated
- Who updates the data
The answers to these questions can lead to choices that can exploit either the frequency, and/or availability of your data to make it easier to manage. A common example of this is when deciding how to cache information in your systems. Some data is write heavy, making it a poor choice for cache while other data might rarely change, be read heavy and the update process might be completely predictable making it a great candidate for caching.
If update frequency of the data is completely in your control and/or deterministic, you have a lot more choices when it comes to how to manage that data.
In the case of Typesense, when it starts up, it reads from its data directory from disk to populate the index in memory and since our index is small and only updates when our documentation is updated, we can simplify the management of the index data by baking it straight into a docker image.
Making our hosted Typesense server read-only, we can build the index and our own Docker image, with the index data in it, as a part of our CI process.
This has several key advantages.
- Disaster recovery doesn’t need any additional data management.
- Shipping an updated index is a normal ECS deployment.
- Zero down time deployments.
- Index is of a fixed size once deployed.
To make things even more simplified, the incremental improvement of our documentation means that the difference between search index between updates is very small. This means if our search index is updated even a day after the actual documentation, the vast majority of our documentation is still accurately searchable by our users.
Search on our documentation site is a very light workload for Typesense. Running as an ECS service on a 2 vCPU instance, the service struggled to get close to 1% with constant typeahead searching.
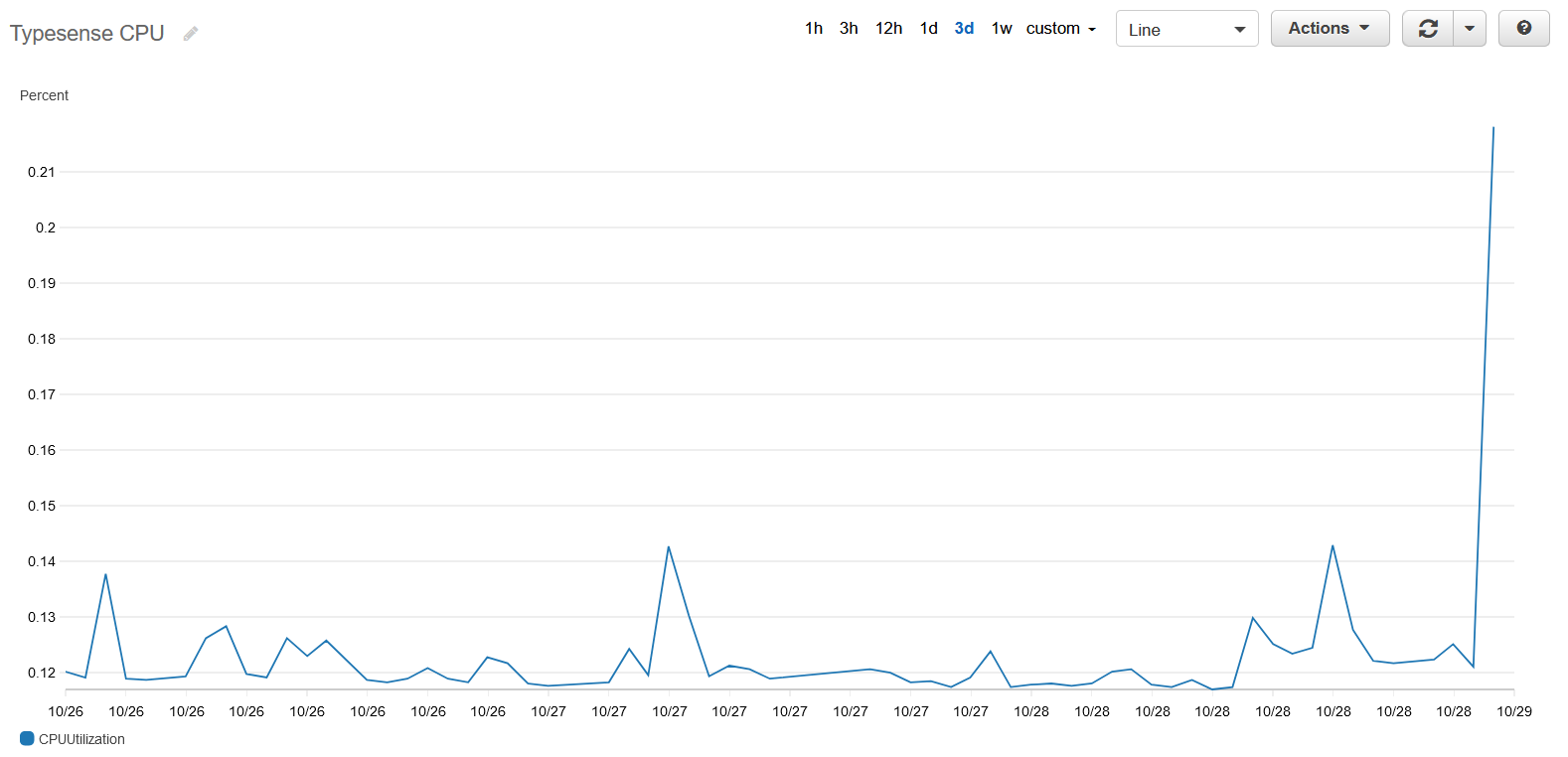
And since our docs site index is so small, the memory footprint is also tiny and stable at ~50MB or ~10% of the the service’s soft memory limit.
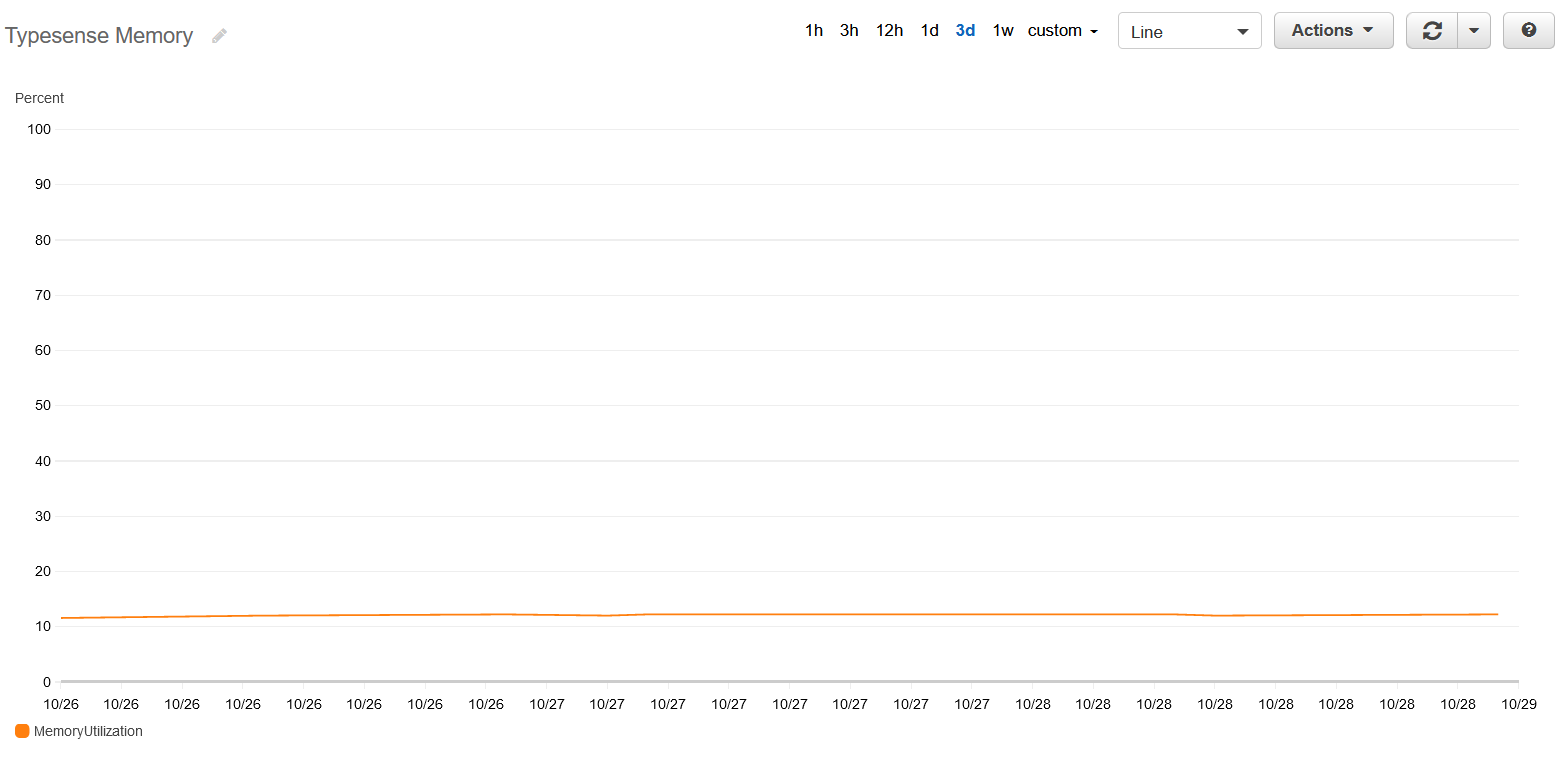
This means we will be able to host this using a single EC2 instance among various other or the ServiceStack hosted example applications and use the same deployment patterns we’ve shared in our GitHub Actions templates.
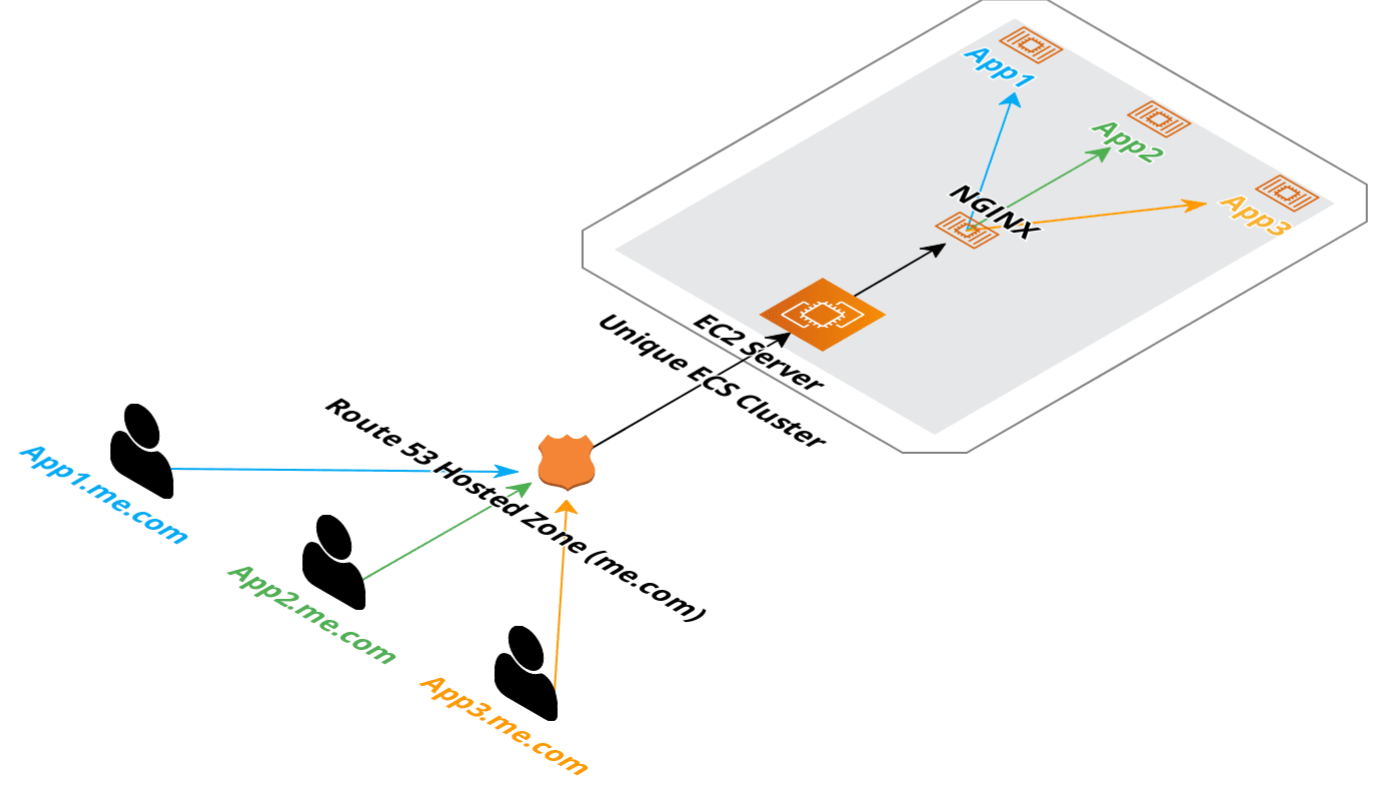
So while this approach of shipping an index along with the Docker image isn’t practical for large or ‘living’ indexes, many opensource documentation sites would likely be able to reuse this simplified approach.
GitHub Actions Process
Since the ServiceStack docs site is hosted using GitHub Pages and we already use GitHub Actions to publish updates to our docs, using GitHub Actions was the natural place for this automation.
To create our own Docker image for our search server we need to perform the following tasks on our CI process.
- Run a local Typesense server on the CI via Docker
- Scrape our hosted docs populating the local Typesense server
- Copy the
datafolder of our local Typesense server duringdocker build
The whole process in GitHub Actions looks like this.
mkdir -p ${GITHUB_WORKSPACE}/typesense-data
cp ./search-server/typesense-server/Dockerfile ${GITHUB_WORKSPACE}/typesense-data/Dockerfile
cp ./search-server/typesense-scraper/typesense-scraper-config.json typesense-scraper-config.json
envsubst < "./search-server/typesense-scraper/typesense-scraper.env" > "typesense-scraper-updated.env"
docker run -d -p 8108:8108 -v ${GITHUB_WORKSPACE}/typesense-data/data:/data \
typesense/typesense:0.21.0 --data-dir /data --api-key=${TYPESENSE_API_KEY} --enable-cors &
# wait for typesense initialization
sleep 5
docker run -i --env-file typesense-scraper-updated.env \
-e "CONFIG=$(cat typesense-scraper-config.json | jq -r tostring)" typesense/docsearch-scraper
Our Dockerfile then takes this data from the data folder during build.
FROM typesense/typesense:0.21.0
COPY ./data /data
One additional problem we had was related to the search only API key generation. As expected when generating API keys, we don’t want the process to generate reused API keys, but to avoid needing to update our search client between updates, we actually want to use the same search only API key everytime we generate a new server.
This can be achieved by specifying value in the POST command sent to the local Typesense server.
curl 'http://172.17.0.2:8108/keys' -X POST \
-H "X-TYPESENSE-API-KEY: ${TYPESENSE_API_KEY}" \
-H 'Content-Type: application/json' \
-d '{"value":<search-api-key>,"description":"Search only","actions":["documents:search"],"collections":["*"]}'
Once our custom Docker image has been built, we deploy it to AWS Elastic Container Repository (ECR), register a new task-defintion.json with ECS pointing to our new image, and finally update the running ECS Service to use the new task definition.
To make things more hands off and reduce any possible issues from GitHub Pages CDN caching, updates to our search index are done on a daily basis using GitHub Action schedule.
Once a day, the process checks if the latest commit in the repository is less than 1 day old. If it is,we ship an updated search index, otherwise we actually cancel the GitHub Action process early to save on CI minutes.
The whole GitHub Action can be seen in our ServiceStack/docs repository if you are interested or are setting up your own process the same way.
Search UI Dialog
Now that our docs are indexed the only thing left to do is display the results. We set out to create a comparable UX to algolia’s doc search which we’ve implemented in custom Vue3 components and have Open sourced in this gist in hope it will serve useful in adopting typesearch for your own purposes.
As VitePress is a SSG framework we need to wrap them in a ClientOnly component to ensure they’re only rendered on the client:
<ClientOnly>
<KeyboardEvents @keydown="onKeyDown" />
<TypeSenseDialog :open="openSearch" @hide="hideSearch" />
</ClientOnly>
Where the logic to capture the window global shortcut keys is wrapped in a hidden KeyboardEvents.vue:
<template>
<div class="hidden"></div>
</template>
<script>
export default {
created() {
const component = this;
this.handler = function (e) {
component.$emit('keydown', e);
}
window.addEventListener('keydown', this.handler);
},
beforeDestroy() {
window.removeEventListener('keydown', this.handler);
}
}
</script>
Which is handled in our custom Layout.vue
VitePress theme to detect when the esc and / or CTRL+K keys are pressed to hide/open the dialog:
const onKeyDown = (e:KeyboardEvent) => {
if (e.code === 'Escape') {
hideSearch();
}
else if ((e.target as HTMLElement).tagName != 'INPUT') {
if (e.code == 'Slash' || (e.ctrlKey && e.code == 'KeyK')) {
showSearch();
e.preventDefault();
}
}
};
The actual search dialog component is encapsulated in TypeSenseDialog.vue (utilizing tailwind classes, scoped styles and inline SVGs so is easily portable), the integral part being the API search query to our typesense instance:
fetch('https://search.docs.servicestack.net/collections/typesense_docs/documents/search?q='
+ encodeURIComponent(query.value)
+ '&query_by=content,hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3&group_by=hierarchy.lvl0', {
headers: {
// Search only API key for Typesense.
'x-typesense-api-key': 'TYPESENSE_SEARCH_ONLY_API_KEY'
}
})
Which instructs Typesense to search through each documents content and h1-3 headings, grouping results by its page title. Refer to the Typesense API Search Reference to learn how to further fine-tune search results for your use-case.
Search Results
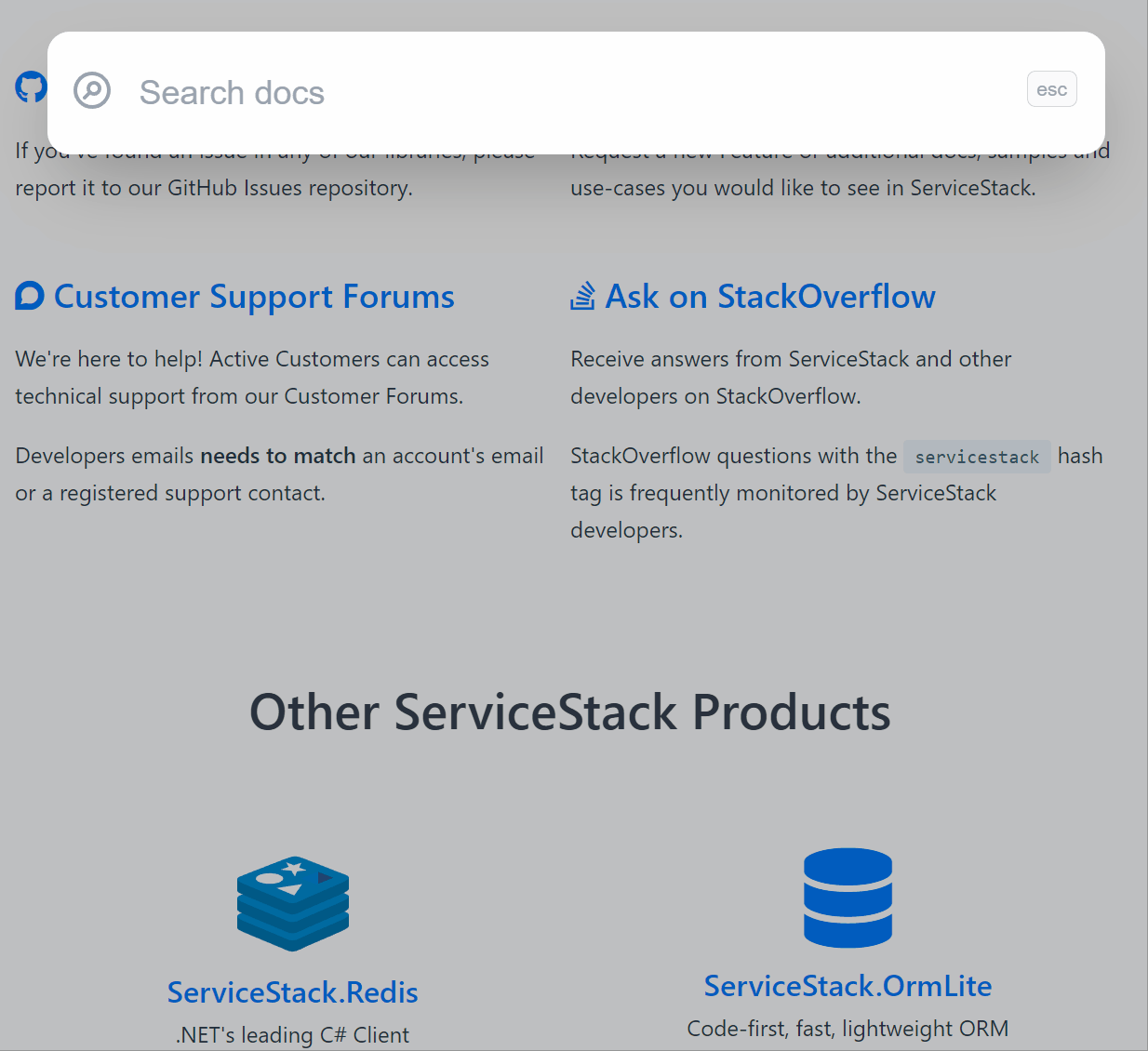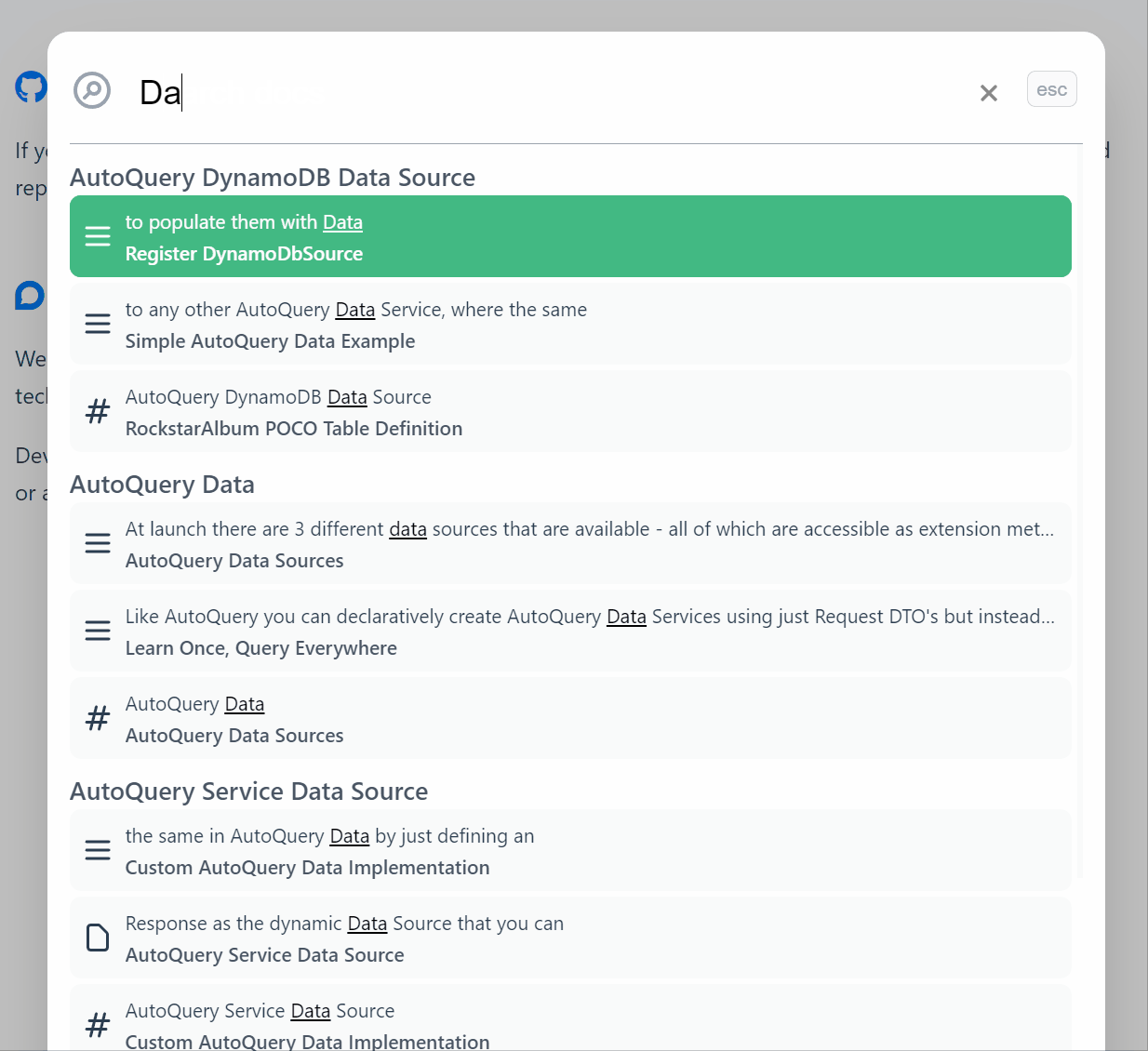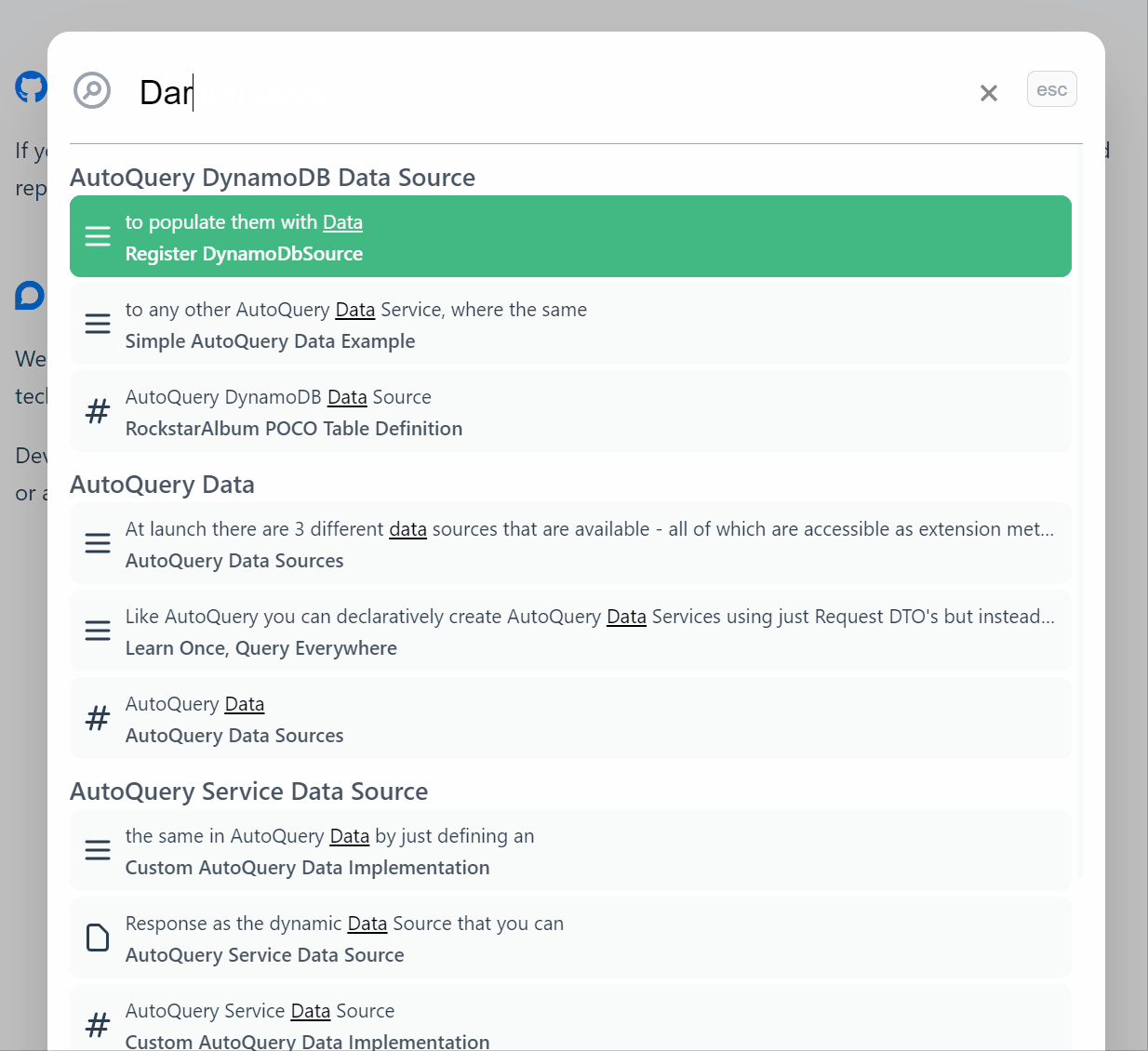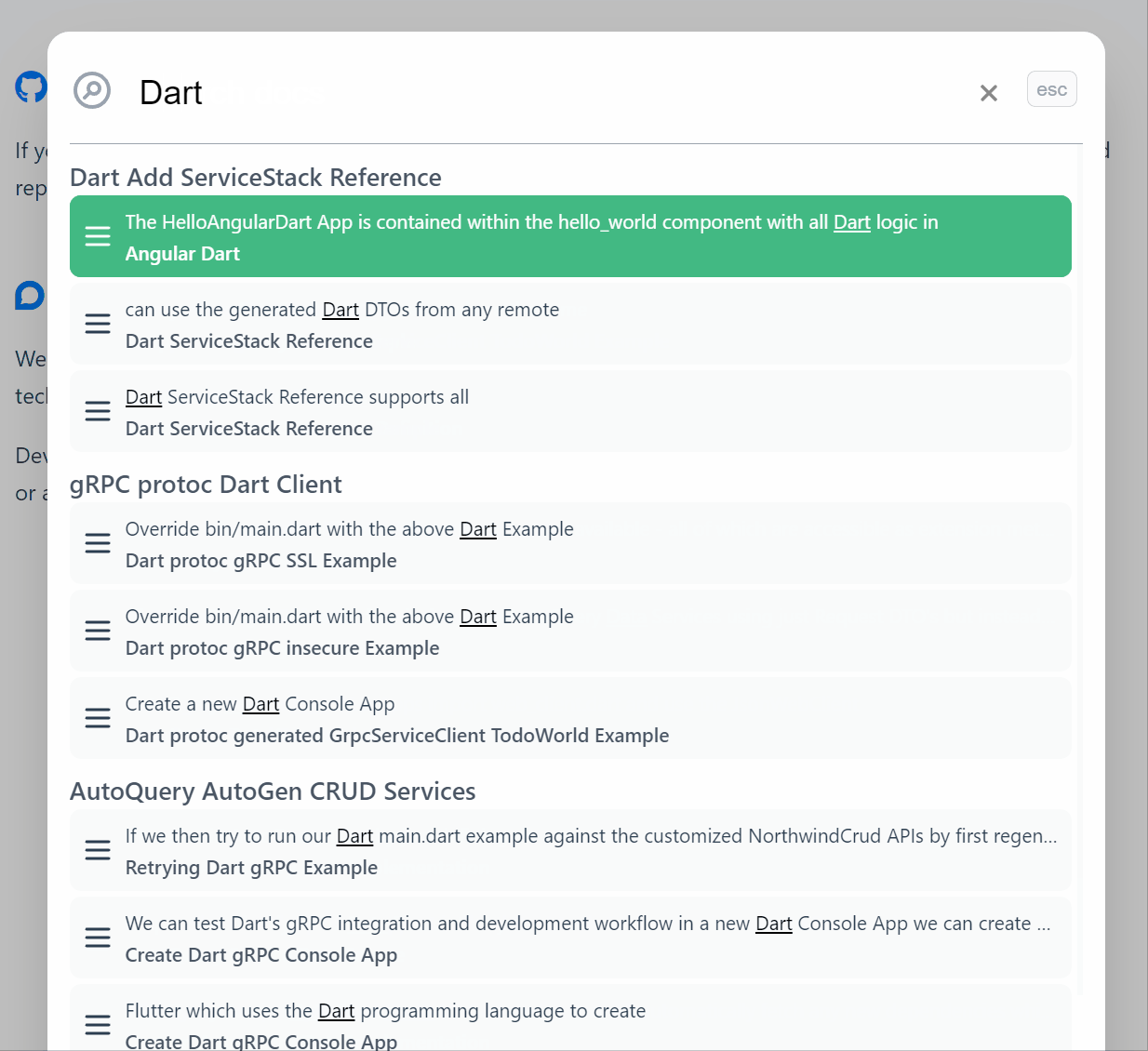
The results are excellent, see for yourself by using the search at the top right or using Ctrl+K shortcut key on our docs site. It handles typos really well, it is very quick and has become the fastest way to navigate our extensive documentation.
We have been super impressed with the search experience that Typesense enabled, the engineers behind the Typesense product have created something with a better developer experience than even paid SaaS options and provided it with a clear value proposition.
ServiceStack a Sponsor of Typesense
We were so impressed by the amazing results, that as a way to show our thanks we’ve become sponsors of Typesense on GitHub sponsors 🎉 🎉
We know how challenging it can be to try make open source software sustainable that if you find yourself using amazing open source products like Typesense which you want to continue to see flourish, we encourage finding out how you or your organization can support them, either via direct contributions or by helping spread the word with public posts (like this) sharing your experiences as their continued success will encourage further investments that ultimately benefits the project and all its users.
