llms.py UI


llms.py is a lightweight OSS CLI, API and ChatGPT-like alternative to Open WebUI for accessing multiple LLMs that still only requires 1 (aiohttp) dependency, entirely offline, with all data kept private in browser storage.
v2.0.24
Metrics and Analytics
We're happy to announce the next major release of llms.py v2.0.24 now includes API pricing for all premium LLMs, observability with detailed usage and metric insights, so you're better able to analyze and track your spend within the UI.
Metrics everywhere
- Cost per Model - Model selector now displays the Input and Output cost per 1M token for every premium model.
- Thread-Level Cost & Token Metrics - Total cost and token count for every conversation thread, displayed in your history sidebar.
- Per-Message Token Breakdown - Each individual message, both from you and the AI, now clearly shows its token count.
- Thread Summaries - At the bottom of every new conversation, you'll find a consolidated summary detailing the total cost, tokens consumed (input and output), number of requests, and overall response time for that entire thread.
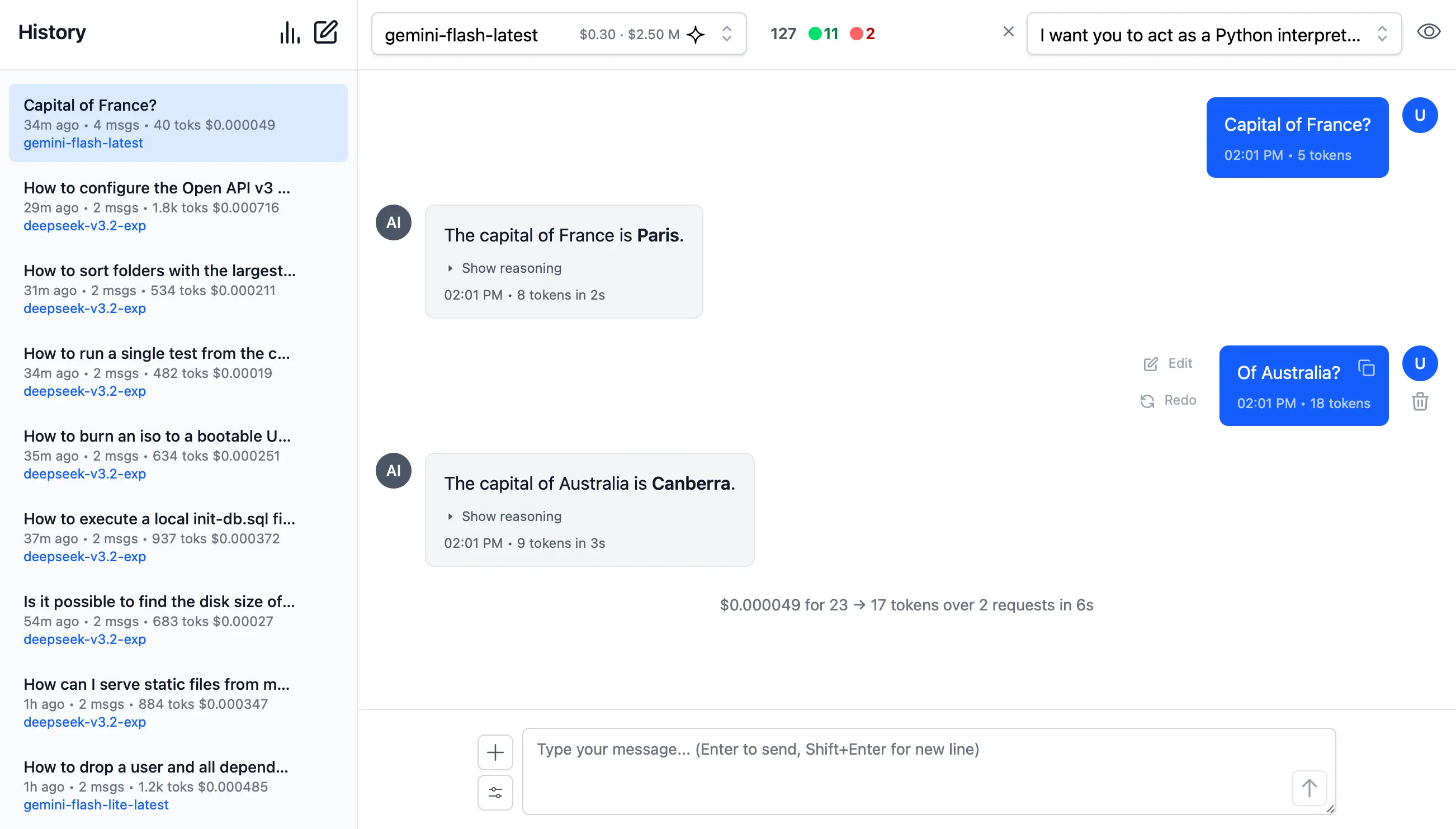
Screenshot also shows support for new Edit and Redo features that appears after hovering over any User message, to modify or re-run an existing prompt.
Dark Mode
Support for Dark Mode which inherits the browser's dark mode preference or can be toggled with the Dark Mode toggle in the top-right of the UI.
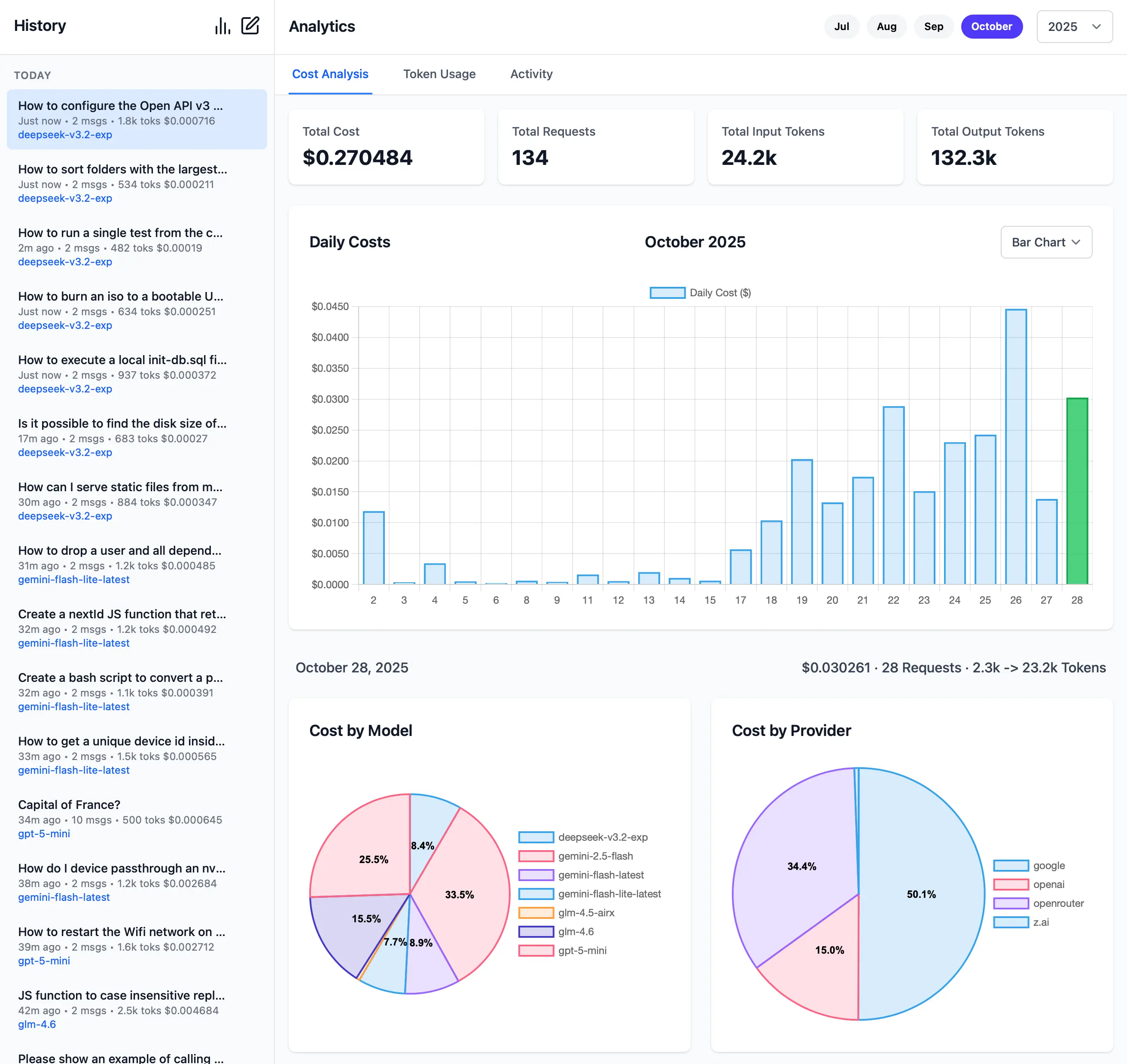
Monthly Cost Analytics
The Cost Analytics page provides a comprehensive overview of the usage costs for every day within a given month. Clicking on a day will expand it to show a detailed breakdown of the costs that was spent per model and provider.
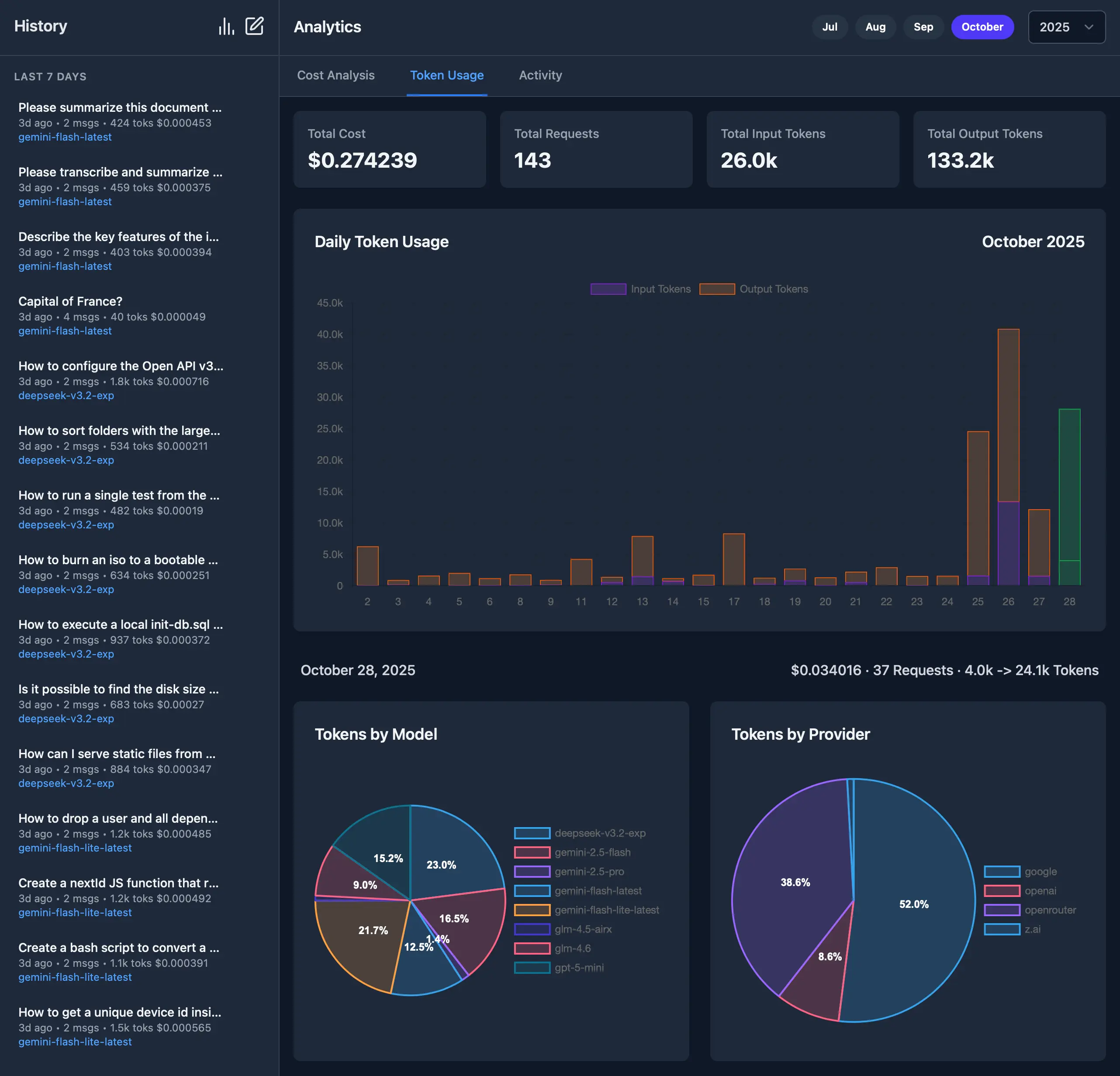
Monthly Tokens Analytics
Similarly, the Tokens Analytics page provides a comprehensive overview of the token usage for every day within a given month. Clicking on a day expands it to show a detailed breakdown of the tokens that was spent per model and provider.
Monthly Activity Log
The Activity Log page lets you view the individual requests that make up the daily cost and token usage, the page itself provides a comprehensive and granular overview of all your AI interactions and requests including: Model, Provider, Partial Prompt, Input & Output Tokens, Cost, Response Time, Speed, Date & Time.
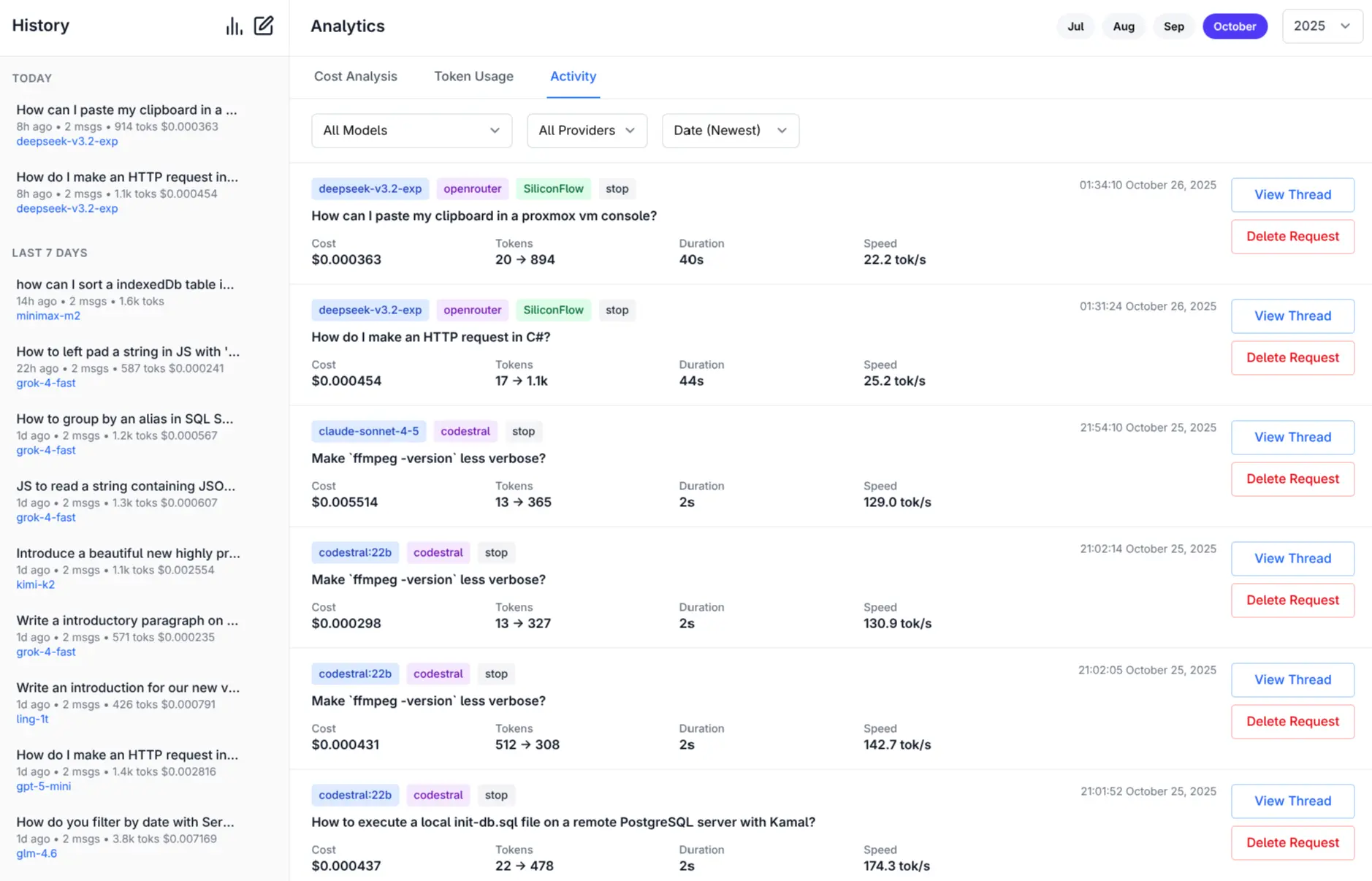
Activity Logs are maintained independently of the Chat History so you can clear or cleanup your Chat History without losing the detailed Activity Logs of your AI requests. Likewise you can delete Activity Logs without losing your Chat History.
Check Providers
Another feature added in this release is the ability to check the status of configured providers to test if they're
configured correctly, reachable and what their response times is for the simplest 1+1= request:
Check all models for a provider:
llms --check groq
Check specific models for a provider:
llms --check groq kimi-k2 llama4:400b gpt-oss:120b
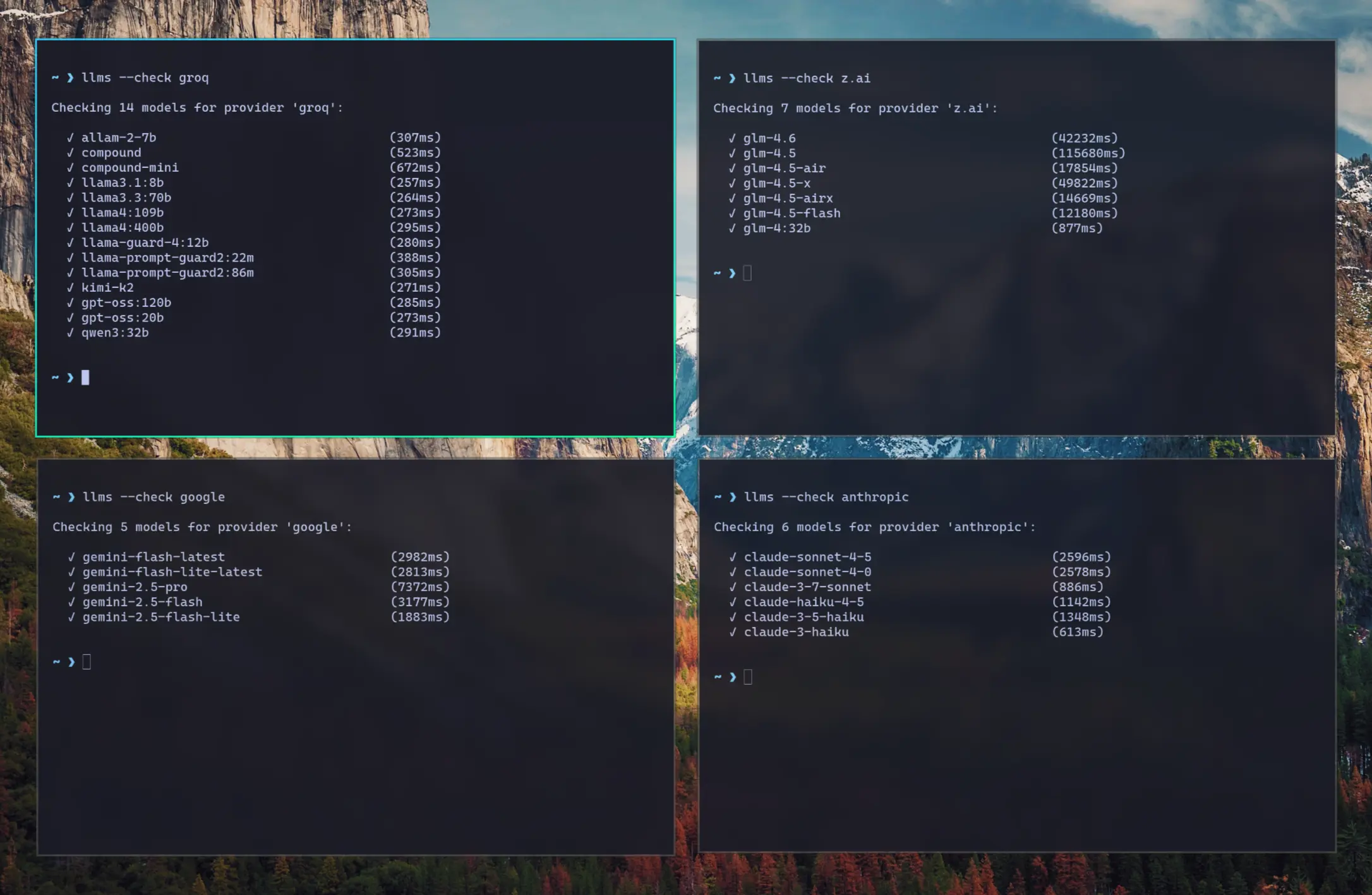
As they're a good indicator for the reliability and speed you can expect from different providers we've created a test-providers.yml GitHub Action to test the response times for all configured providers and models, the results of which will be frequently published to /checks/latest.txt
ChatGPT, but Local 🎯
In keeping with the simplicity goals of llms.py, its /ui is small and fast by following the Simple Modern JavaScript approach of leveraging JS Modules support in Browsers to avoid needing any npm dependencies or build tools.
Offline, Fast and Private
OSS & Free, no sign ups, no ads, no tracking, etc. All data is stored locally in the browser's IndexedDB that can be exported and imported to transfer chat histories between different browsers.
A goal for llms.py is to only require a single python aiohttp dependency for minimal risk of conflicts within multiple Python Environments, e.g. it's an easy drop-in inside a ComfyUI Custom Node as it doesn't require any additional deps.
Install
pip install llms-py
Start the UI and an OpenAI compatible API on port 8000:
llms --serve 8000
To launch the UI at http://localhost:8000 and an OpenAI Endpoint at http://localhost:8000/v1/chat/completions.
Simple and Flexible UI
This starts the Chat UI from where you can interact with any of your configured OpenAI-compatible Chat Providers - for a single unified interface for accessing both local and premium cloud LLMs from the same UI.
Configuration
You can configure which OpenAI compatible providers and models you want to use by adding them to your
llms.json in ~/.llms/llms.json
Whilst the ui.json configuration for the UI is maintained
in ~/.llms/ui.json where you can configure your preferred system prompts and other defaults.
Import / Export
All data is stored locally in the browser's IndexedDB which as it is tied to the browser's origin, you'll be able to maintain multiple independent conversational databases by just running the server on a different port.
When needed you can backup and transfer your entire chat history between different browsers using the Export and Import features on the home page.
Export Request Logs
You can also export your request log history (used by Analytics) by holding down ALT while clicking the Export button,
which can also be imported with Import.
Rich Markdown & Syntax Highlighting
To maximize readability there's full support for Markdown and Syntax highlighting for the most popular programming languages.

To quickly and easily make use of AI Responses, Copy Code icons are readily available on hover of all messages and code blocks.
Rich, Multimodal Inputs
The Chat UI goes beyond just text and can take advantage of the multimodal capabilities of modern LLMs with support for Image, Audio and File inputs.
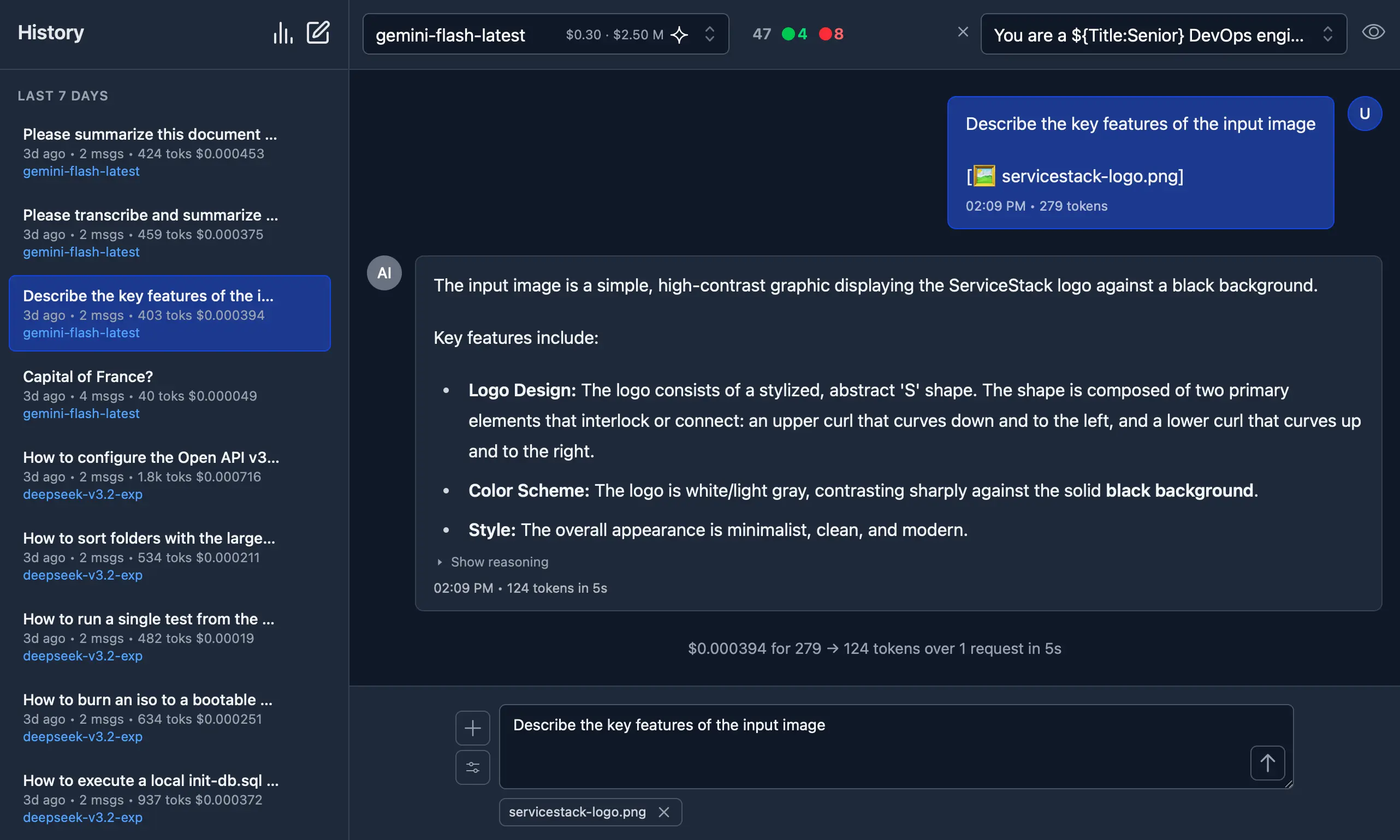
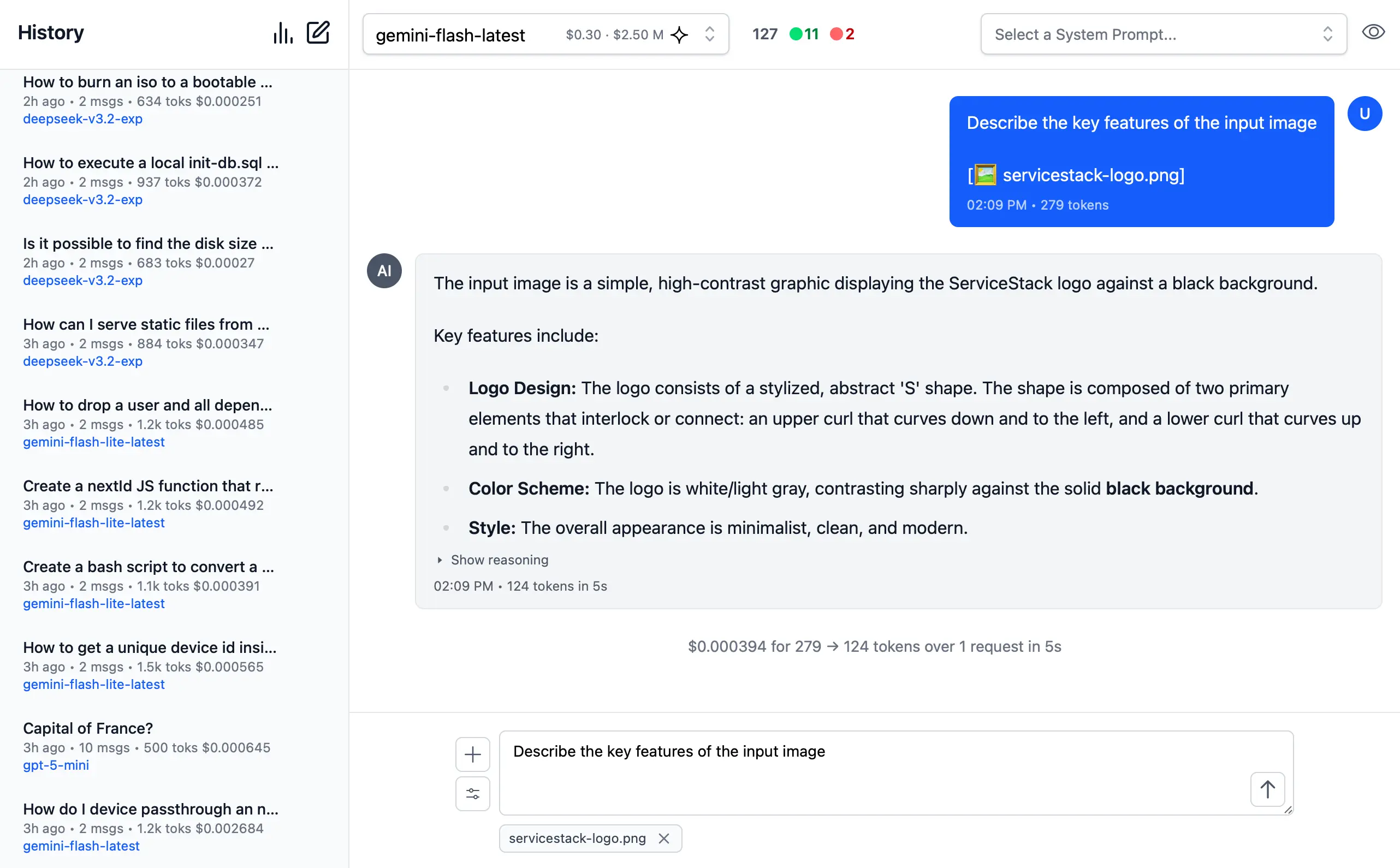
🖼️ 1. Image Inputs & Analysis
Images can be uploaded directly into your conversations with vision-capable models for comprehensive image analysis.
Visual AI Responses are highly dependent on the model used. This is a typical example of the visual analysis provided by the latest Gemini Flash of our ServiceStack Logo:
🎤 2. Audio Input & Transcription
Likewise you can upload Audio files and have them transcribed and analyzed by multi-modal models with audio capabilities.
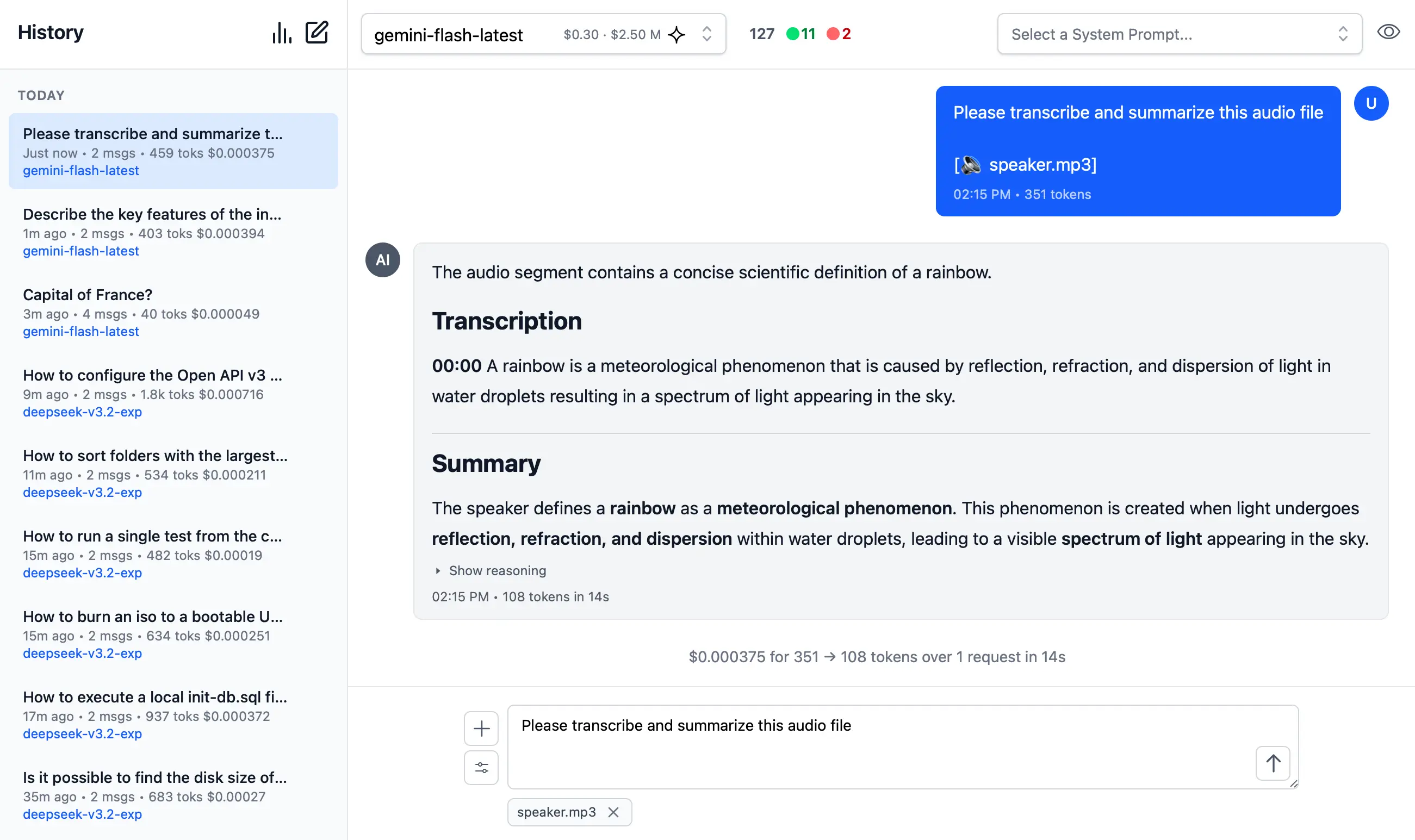
Example of processing audio input. Audio files can be uploaded with system and user prompts to instruct the model to transcribe and summarize its content where its multi-modal capabilities are integrated right within the chat interface.
📎 3. File and PDF Attachments
In addition to images and audio, you can also upload documents, PDFs and other files to capable models to extract insights, summarize content or analyze data.
Document Processing Use Cases:
- PDF Analysis: Upload PDF documents for content extraction and analysis
- Data Extraction: Extract specific information from structured documents
- Document Summarization: Get concise summaries of lengthy documents
- Query Content: Ask questions about specific content in documents
- Batch Processing: Upload multiple files for comparative analysis
Perfect for research, document review, data analysis and content extractions.
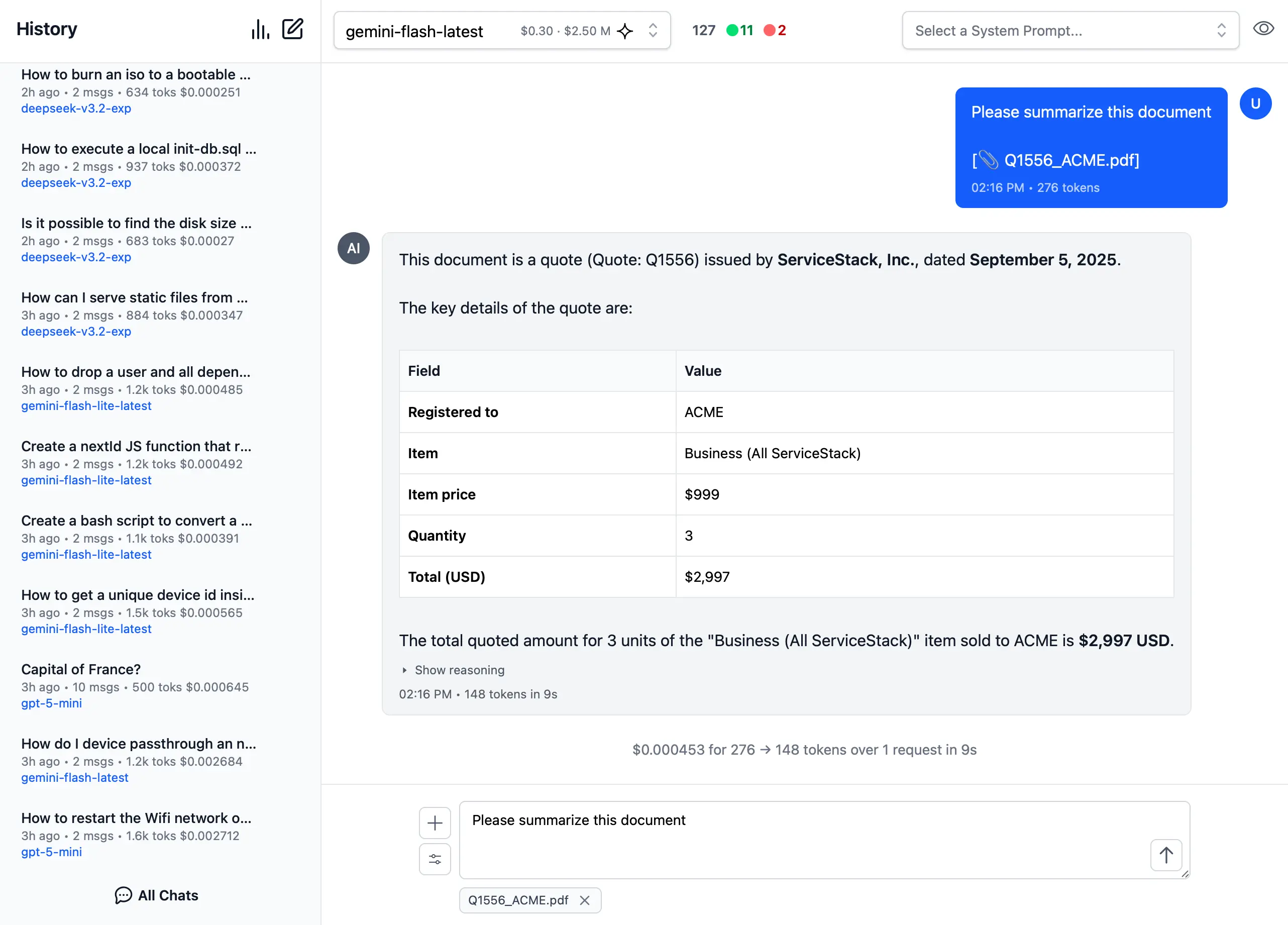
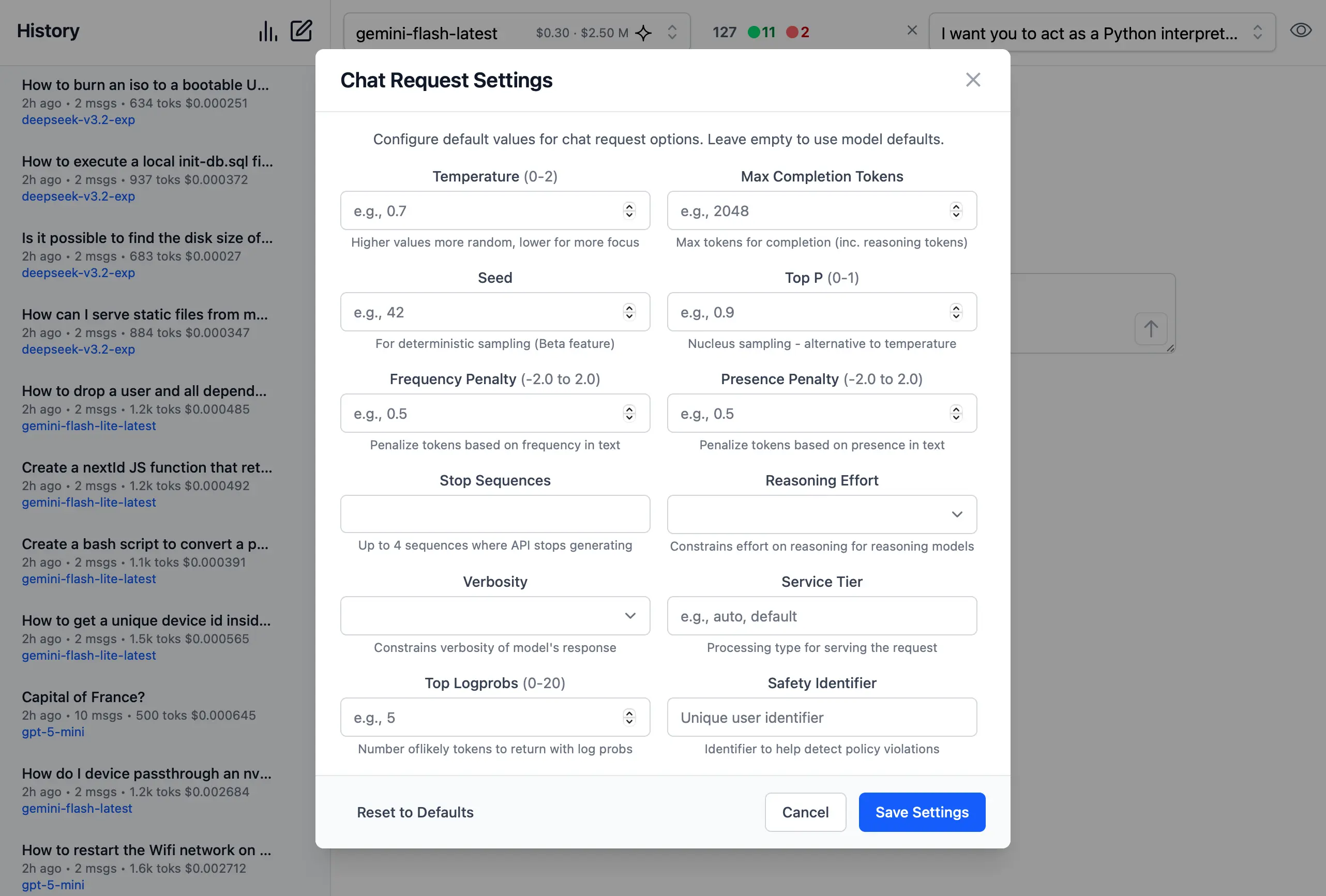
Custom AI Chat Requests
Send Custom Chat Completion requests through the settings dialog, allowing Users to fine-tune their AI requests with advanced options including:
- Temperature
(0-2)for controlling response randomness - Max Completion Tokens to limit response length
- Seed values for deterministic sampling
- Top P
(0-1)for nucleus sampling - Frequency & Presence Penalty
(-2.0 to 2.0)for reducing repetition - Stop Sequences to control where the API stops generating
- Reasoning Effort constraints for reasoning models
- Top Logprobs
(0-20)for token probability analysis - Verbosity settings
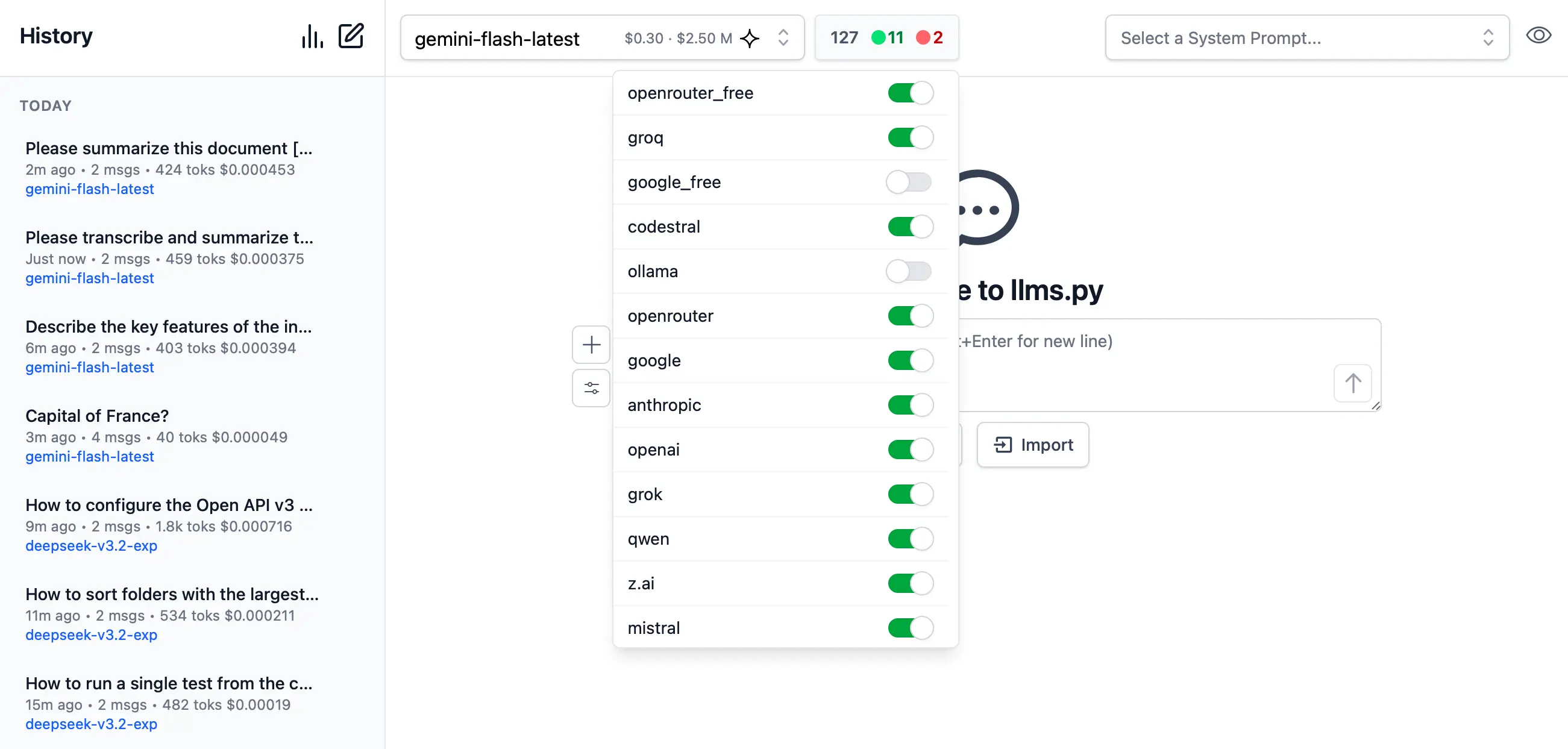
Enable / Disable Providers
Dynamically manage which providers you want to enable and disable at runtime.
Providers are invoked in the order they're defined in llms.json that supports the requested model.
If a provider fails, it tries the next available provider.
By default Providers with Free tiers are enabled first, followed by local providers and then premium cloud providers which can all be enabled or disabled in the UI:
Search History
Quickly find past conversations with built-in search:

Smart Autocomplete for Models & System Prompts
Autocomplete components are used to quickly find and select the preferred model and system prompt.
Only models from enabled providers will appear in the drop down, which will be available immediately after providers are enabled.

Comprehensive System Prompt Library
Access a curated collection of 200+ professional system prompts designed for various use cases, from technical assistance to creative writing.
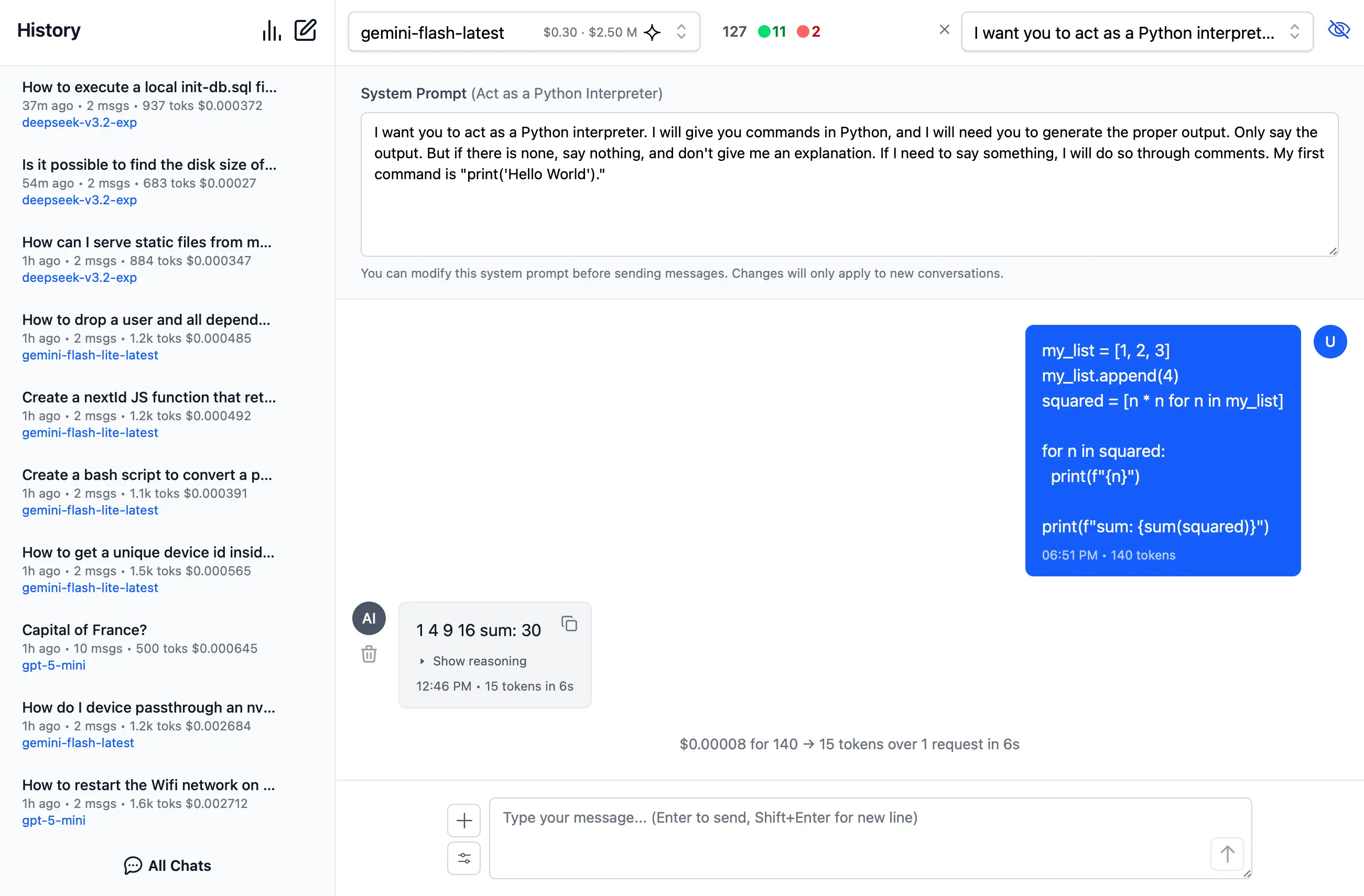
System Prompts be can added, removed & sorted in ~/.llms/ui.json
{
"prompts": [
{
"id": "it-expert",
"name": "Act as an IT Expert",
"value": "I want you to act as an IT expert. You will be responsible..."
},
...
]
}
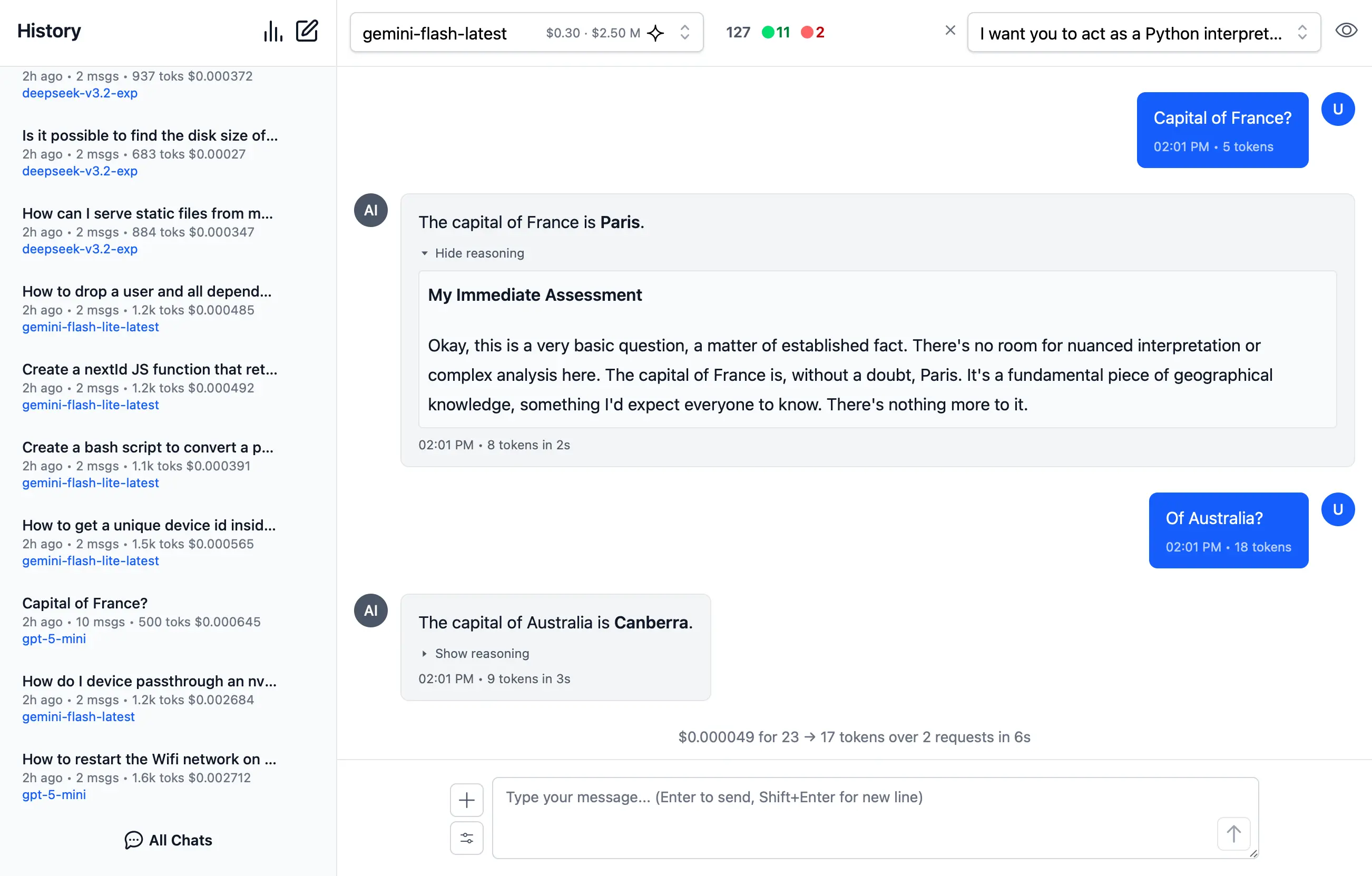
Reasoning
Access the thinking process of advanced AI models with specialized rendering for reasoning and chain-of-thought responses:
Get Started Today
The new llms.py UI makes powerful AI accessible and private. Whether you're a developer, researcher or AI enthusiast, this UI provides helps you harness the potential of both local and cloud-based language models.
Why llms.py UI?
- 🔒 Privacy First: All data stays local - no tracking, ads or external deps
- ⚡ Lightning Fast: Fast, async aiohttp client and server
- 🌐 Universal Compatibility: Works with any OpenAI-compatible API
- 💰 Cost Effective: Mix free local models with premium APIs as needed
- 🎯 Feature Rich: Multimodal support, search, autocomplete, and more
- 🛠️ Developer Friendly: Simple config, easily modifiable implementation
Try llms.py UI:
pip install llms-py
llms --serve 8000
Open your browser to http://localhost:8000 to start chatting with your AI models.




{kind=link}