AI Server - May 2025 Update


AI Server is our Free OSS Docker self-hosted private gateway to manage API access to multiple LLM APIs, Ollama endpoints, Media APIs, Comfy UI and FFmpeg Agents that's designed as a one-stop solution to manage an organization's AI integrations for all their System Apps with its developer friendly HTTP JSON APIs that supports any programming language or framework.

Built in Analytics & Logging
We've brought comprehensive Analytics added in ServiceStack v5.7 into AI Server's Admin UI to provide deep and invaluable insight into your System API Usage, device distribution, API Keys and identify IPs where most traffic generates.
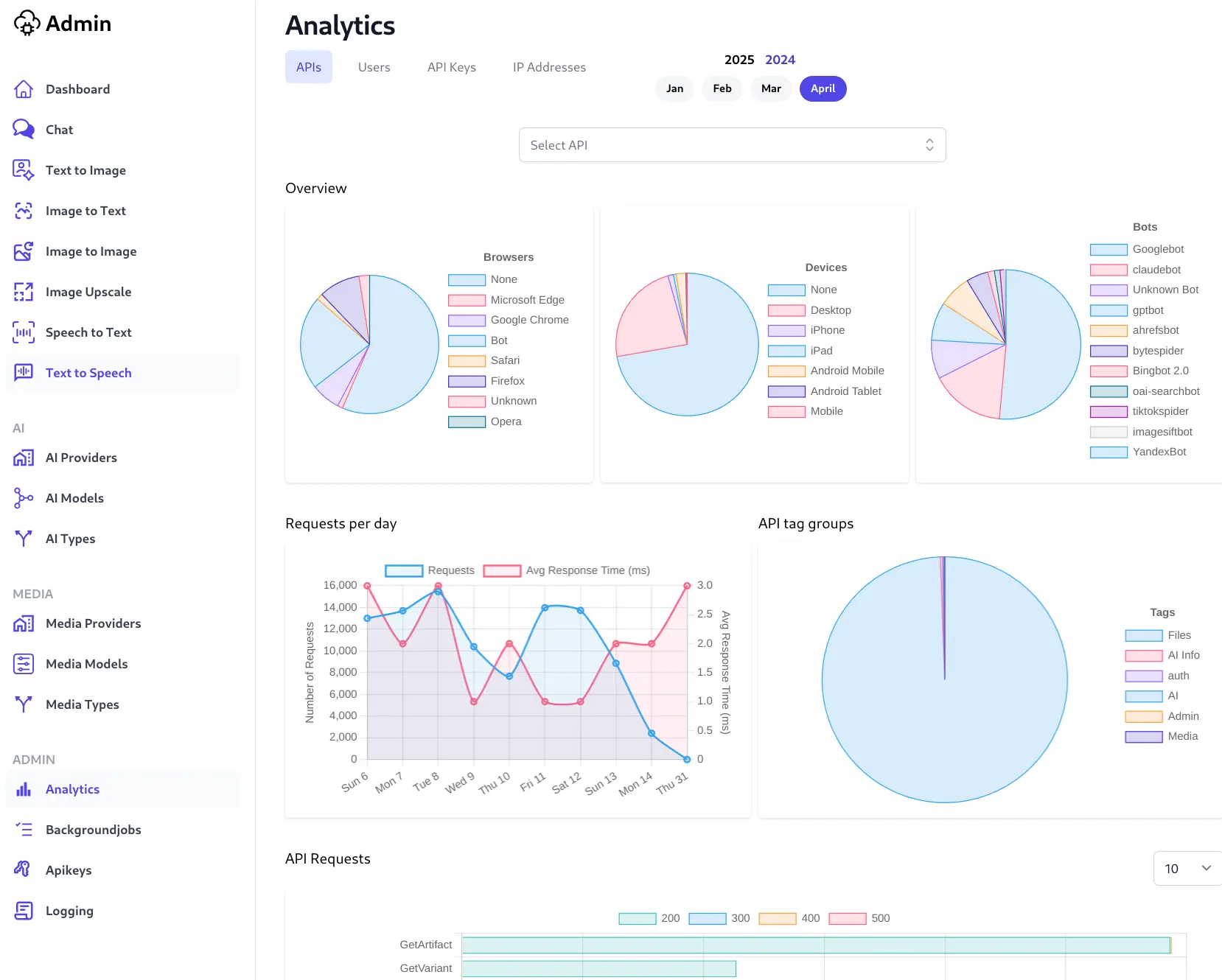
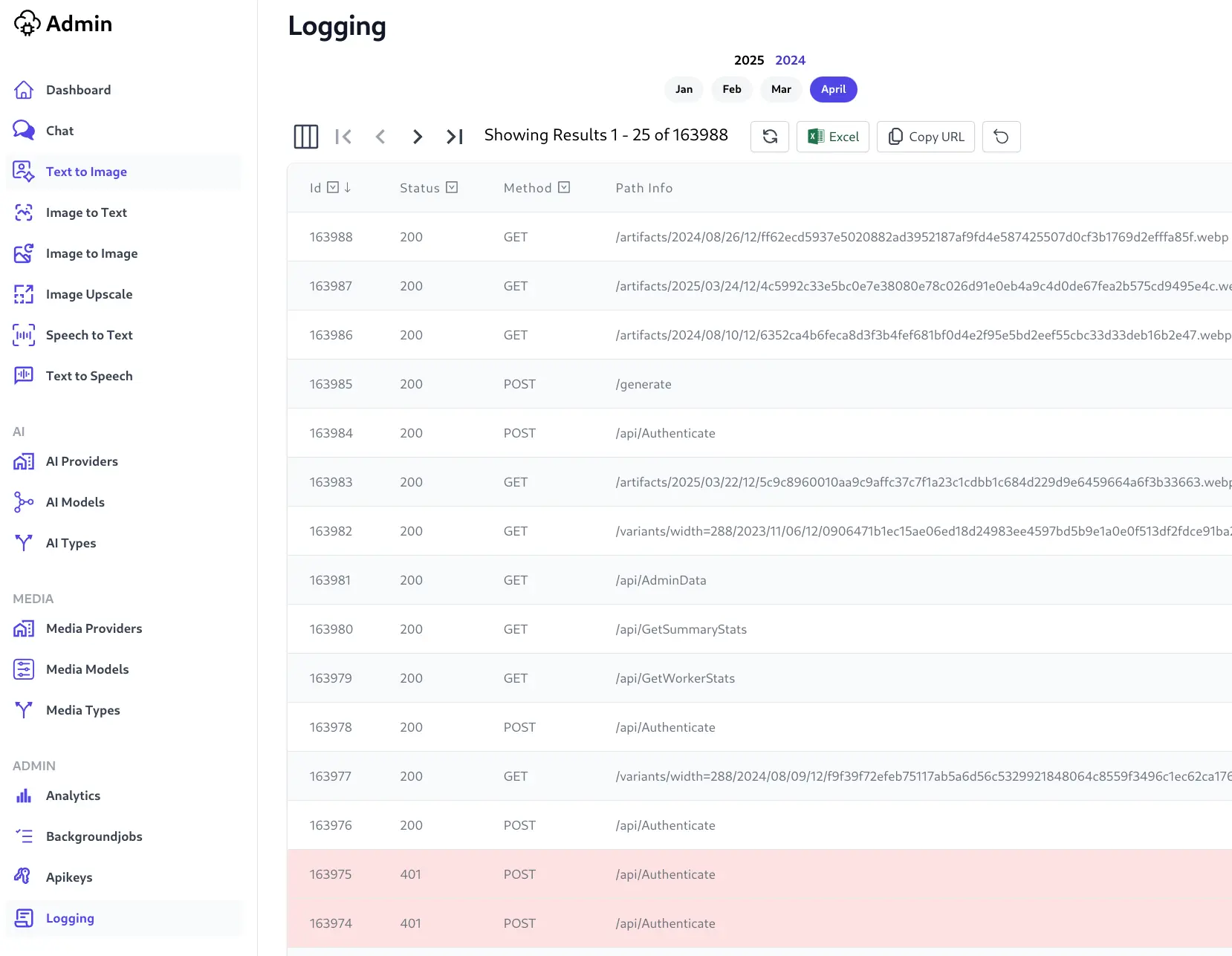
For even finer grained detail of your AI Server's usage we've also surfaced the SQLite Request Logs functionality inside AI Server's Admin UI which lets you monitor your API System usage in real-time:
Redesigned UI
As AI Server gains more features it became necessary to group UI features under group headings and associated sub menus:
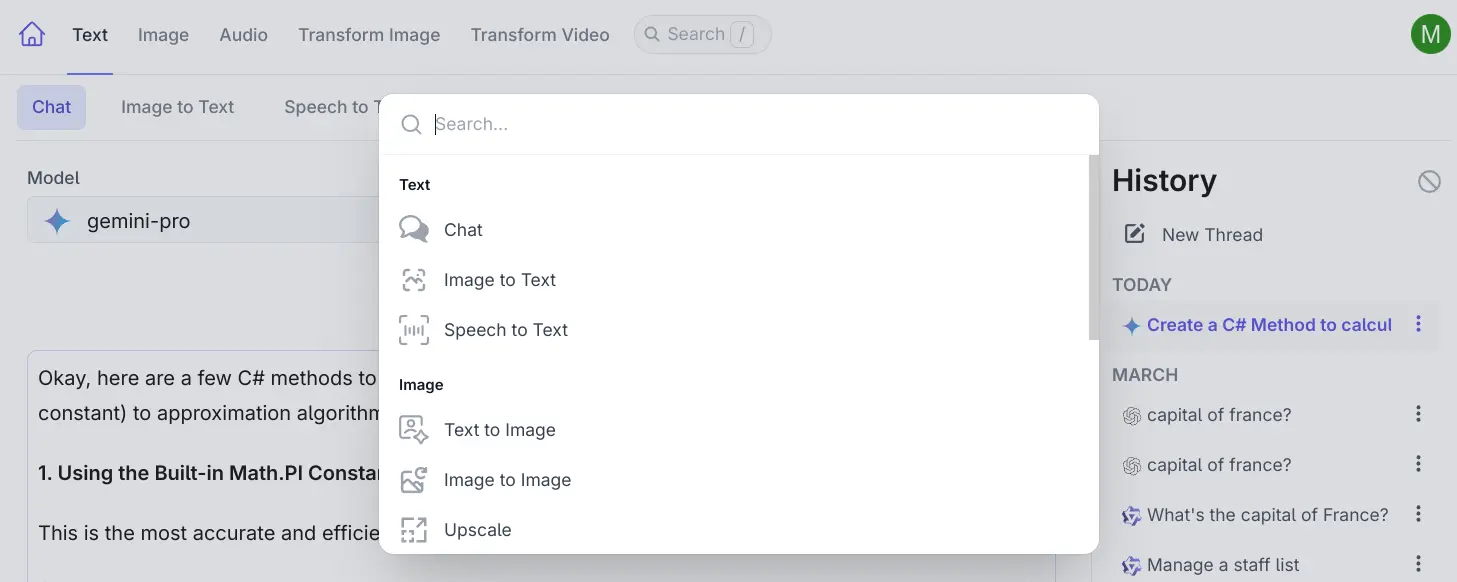
Command Palette
A new Command Palette has been added to quickly navigate between AI Server's different user-facing features
which can be opened with the / key:
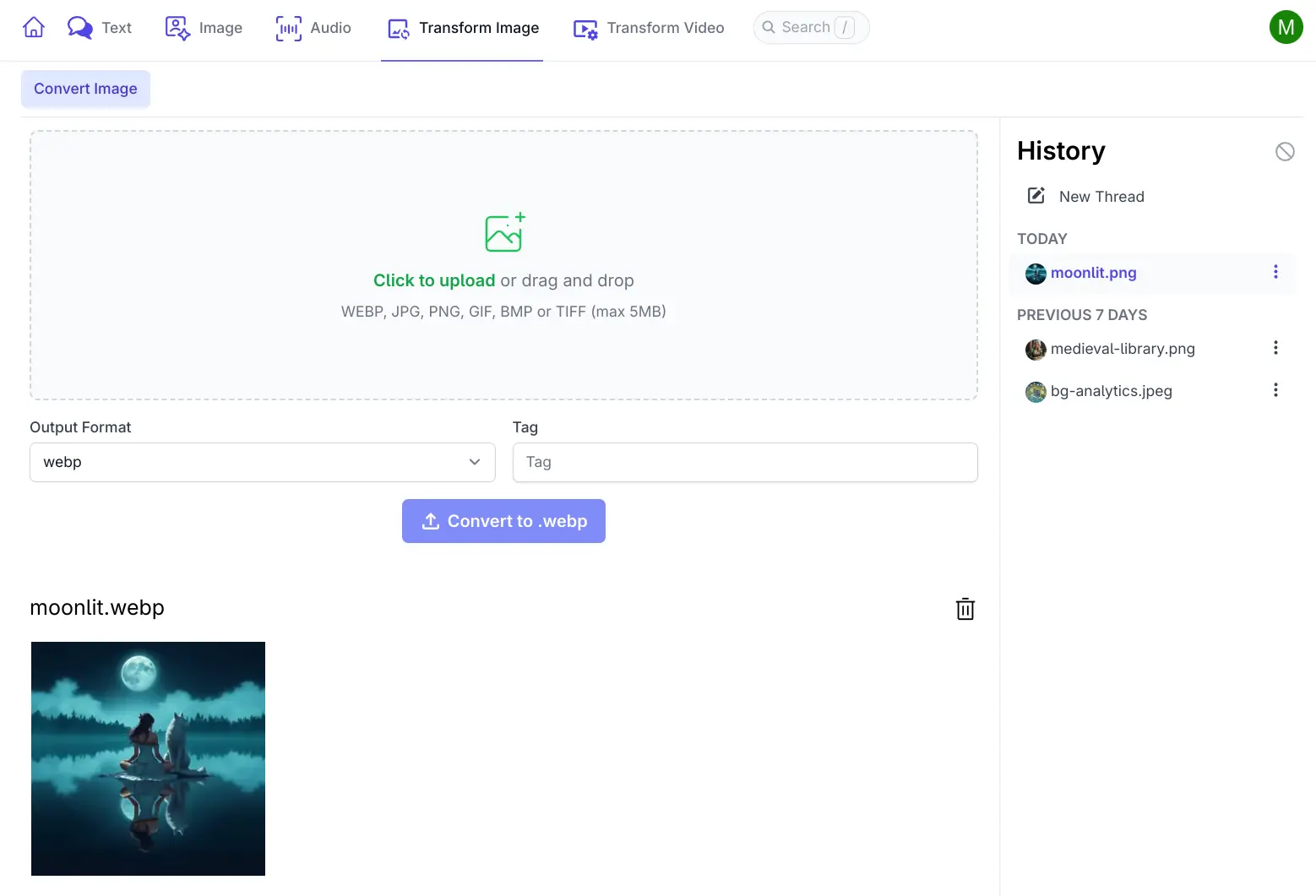
Convert Image
AI Server has now added a UI to convert images between different image formats:
.png, .jpg, .gif, .bmp, .tiff and .webp
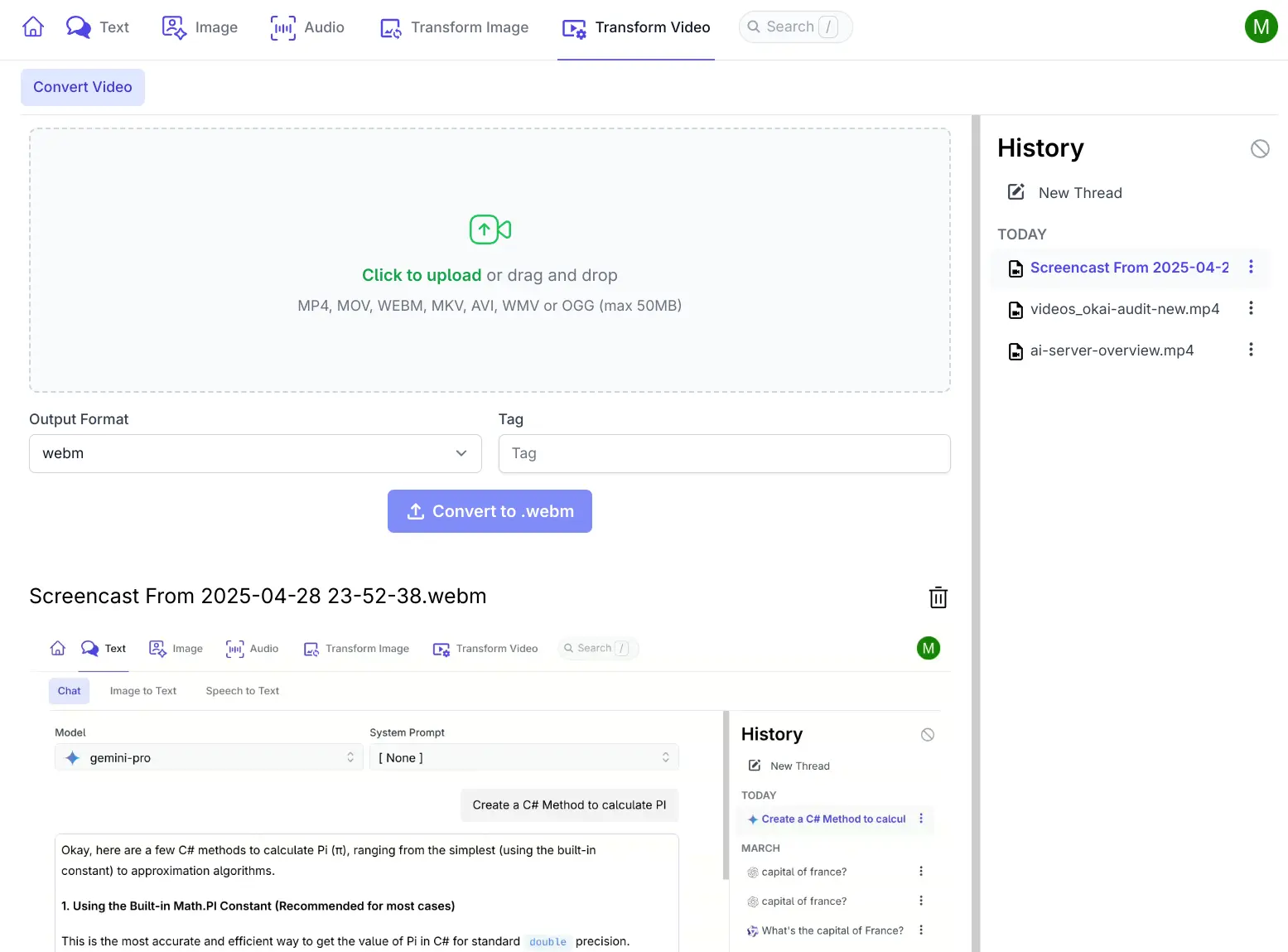
Convert Video
AI Server configured with a Media Provider can also convert between different video formats:
.mp4, .mov, .webm, .mkv, .avi, .wmv and .ogg:
Support for new Models
This release continues to see a number of improvements to AI Server starting with adding support for popular LLM models added during this release, including:
- Google: gemini-flash-2.5, gemini-pro-2.5, gemini-flash-lite-2.0, gemini-flash-thinking-2.0, gemma3
- OpenAI: o3, o4-mini, gpt-4.1, gpt-4.1-mini, gpt-4.1-nano
- Alibaba: qwen3, qwen-turbo, qwen-plus, qwen-max
- Meta: llama-4-scout, llama-4-maverick
- Microsoft: phi4
- Mistral: mistral-small, mistral-saba
Custom OpenAI Endpoints
Prior to this release AI Requests were only able to reference LLM Models defined in AI Server's pre-defined ai-models.json or included in your overrides folder.
Model definitions facilitate load balancing requests for a specific model across multiple AI Providers utilizing different model names back to a single model definition.
This approach makes it harder to run custom or fine-tuned models from OpenAI Compatible Chat Endpoints which don't map to an existing model definition. To better support these use-cases AI Server now supports registering a custom OpenAI Chat compatible endpoints with custom models with the new Custom AI Provider Type:
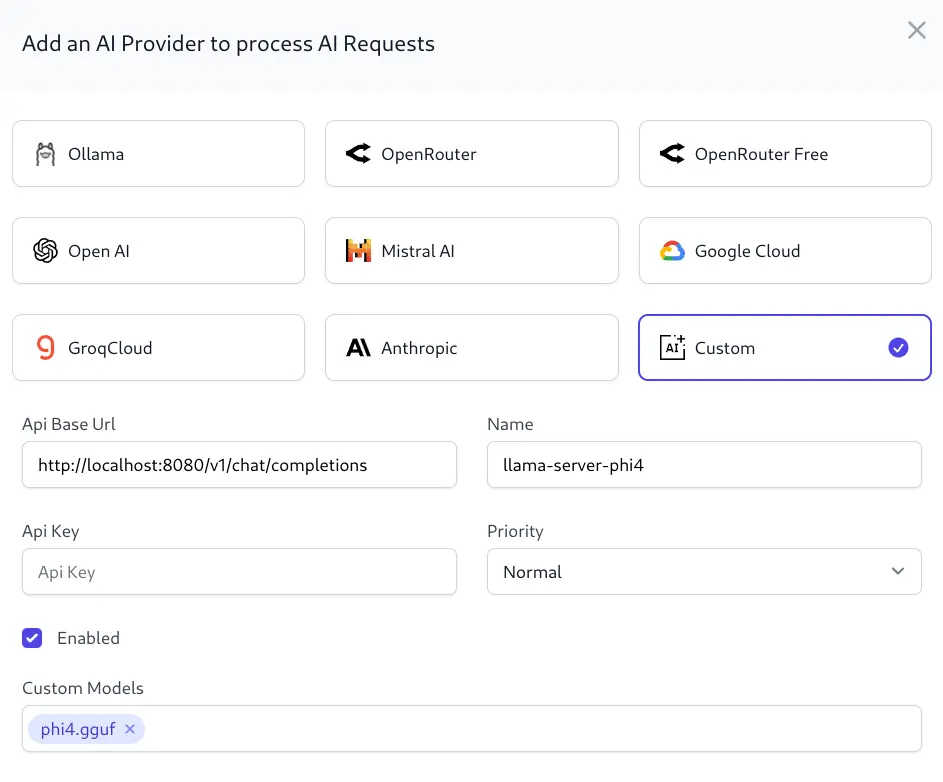
This now lets AI Server connect with other OpenAI Compatible API's like llama.cpp's llama-server, e.g:
CUDA_VISIBLE_DEVICES=0 llama-server --model ./models/phi-4-q4.gguf -ngl 999 --port 8080
Which launches an OpenAI compatible API configured to serve a single model that's run entirely on an NVidia GPU at port 8080.
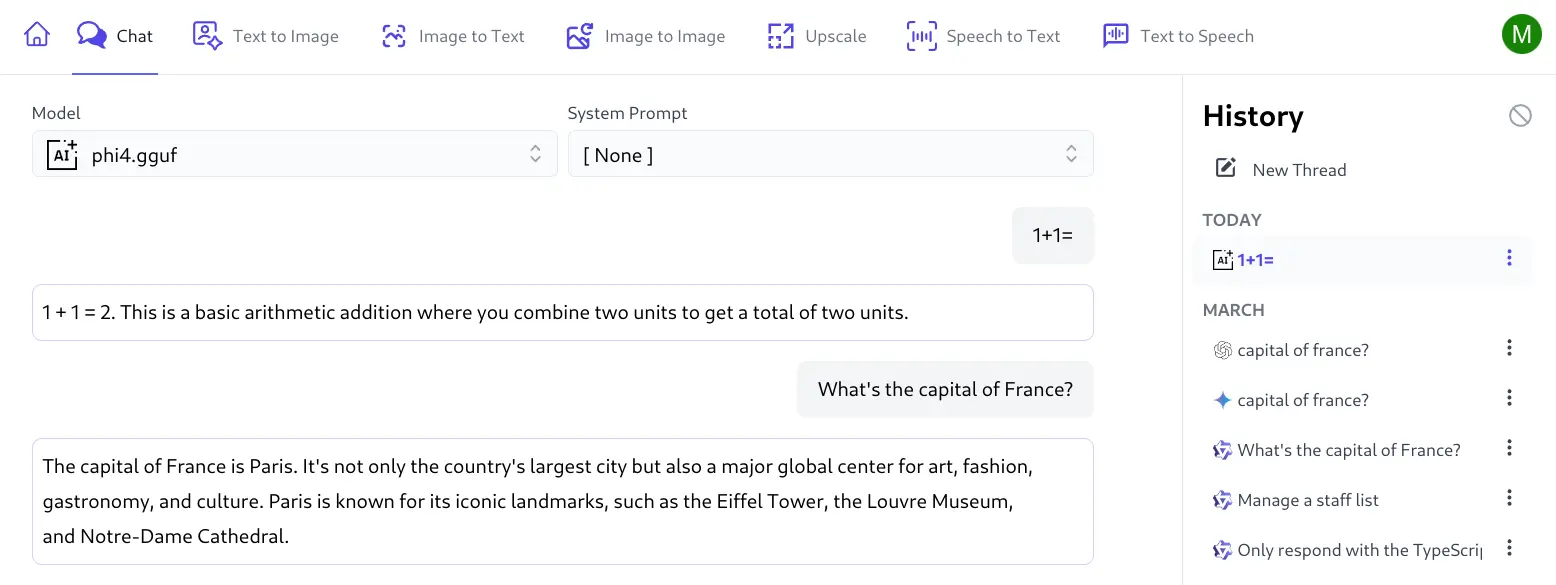
As it's only configured to serve a single model you can choose to configure it with any model name you wish which llama-server ignores but AI Server uses to route any AI requests for that model to the custom AI Provider instance which you can try in AI Server's Chat UI:
Support for Ollama Vision Models
By default ImageToText uses a purpose-specific Florence 2 Vision model with ComfyUI for its functionality which is capable of generating a very short description about an image, e.g:
A woman sitting on the edge of a lake with a wolf
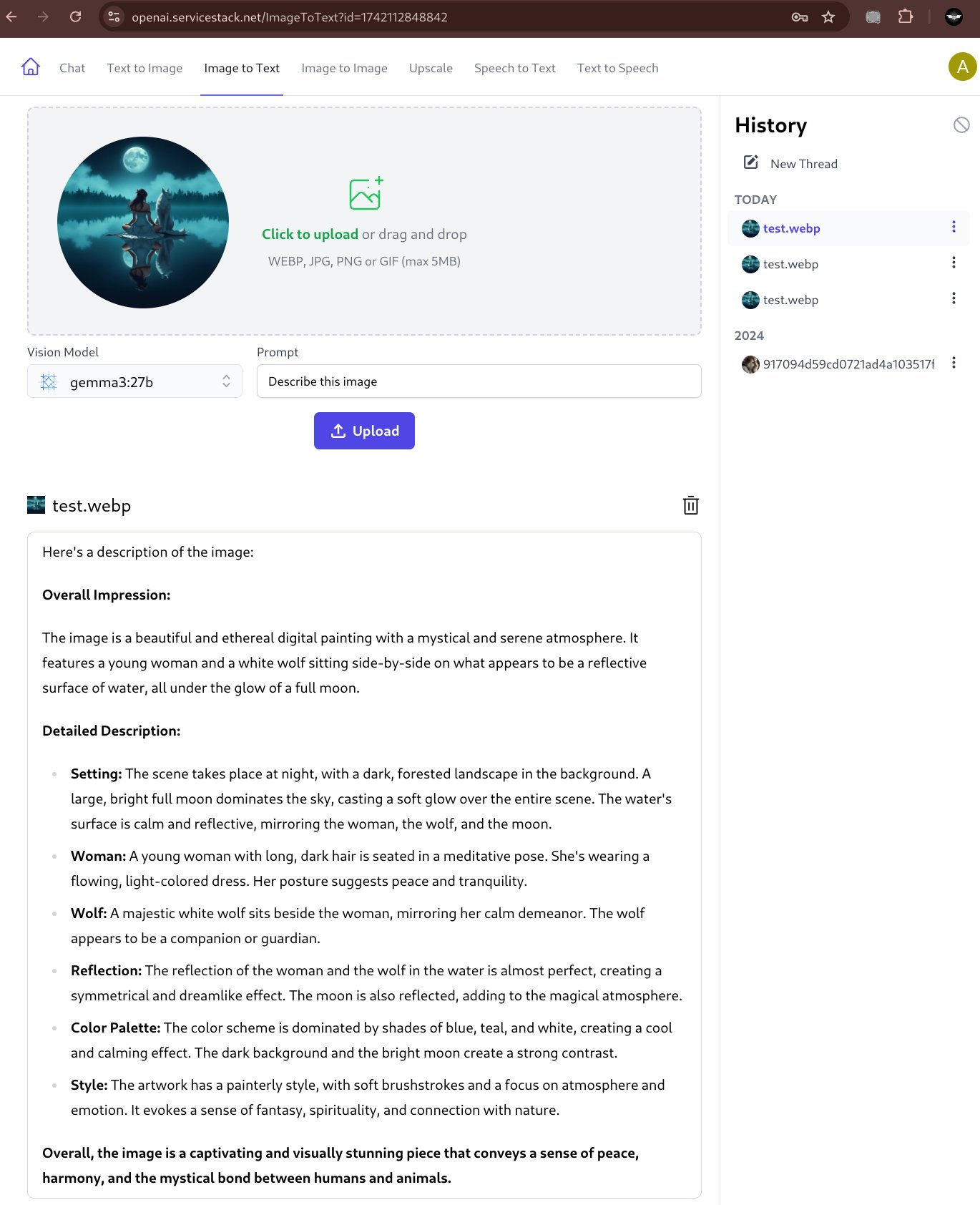
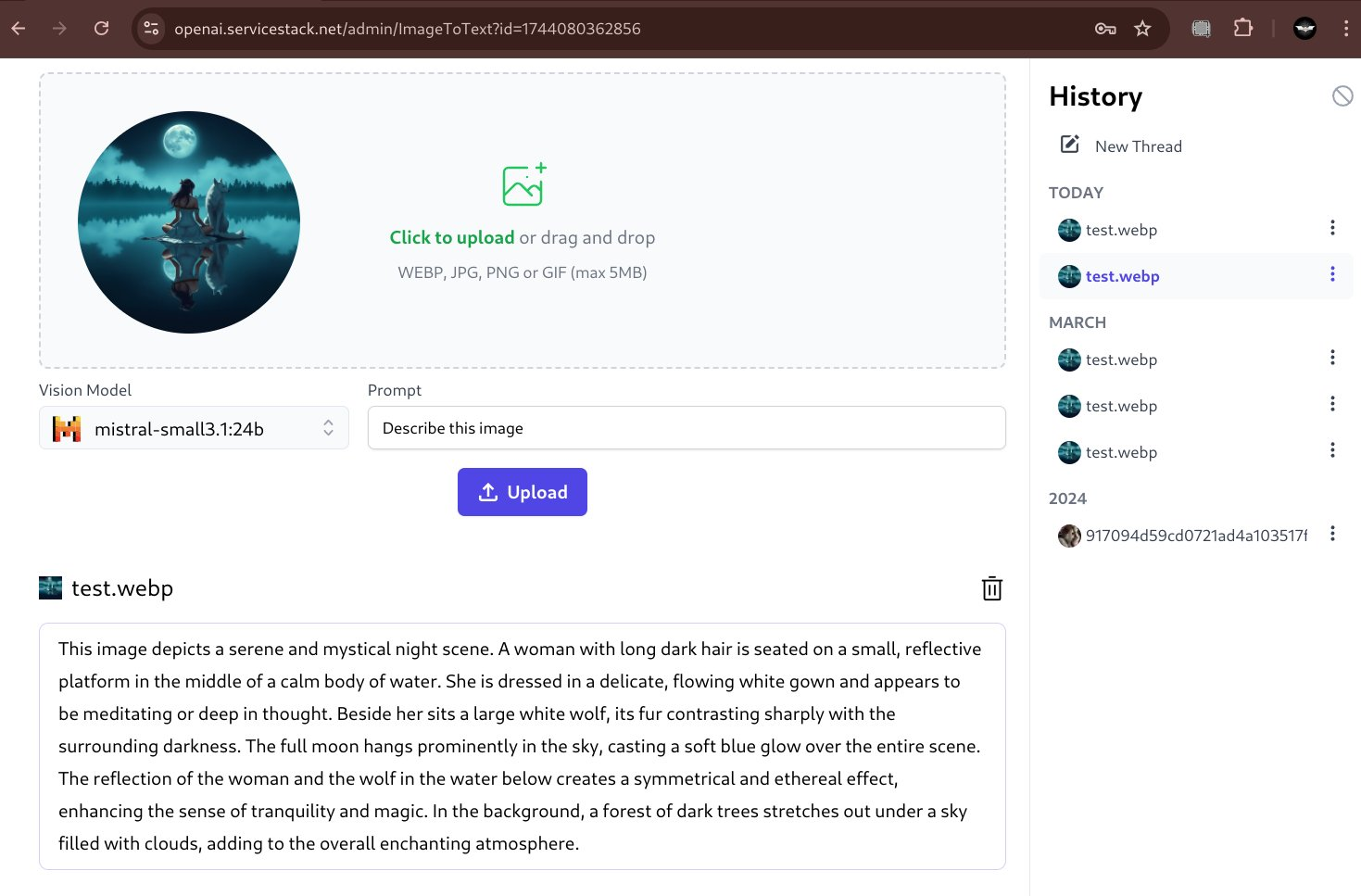
But with LLMs gaining multi modal capabilities and Ollama's recent support of Vision Models we can instead use popular Open Source models like Google's gemma3:27b or Mistral's mistral-small:24b to extract information from images.
Both models are very capable vision models that's can provide rich detail about an image:
Describe Image
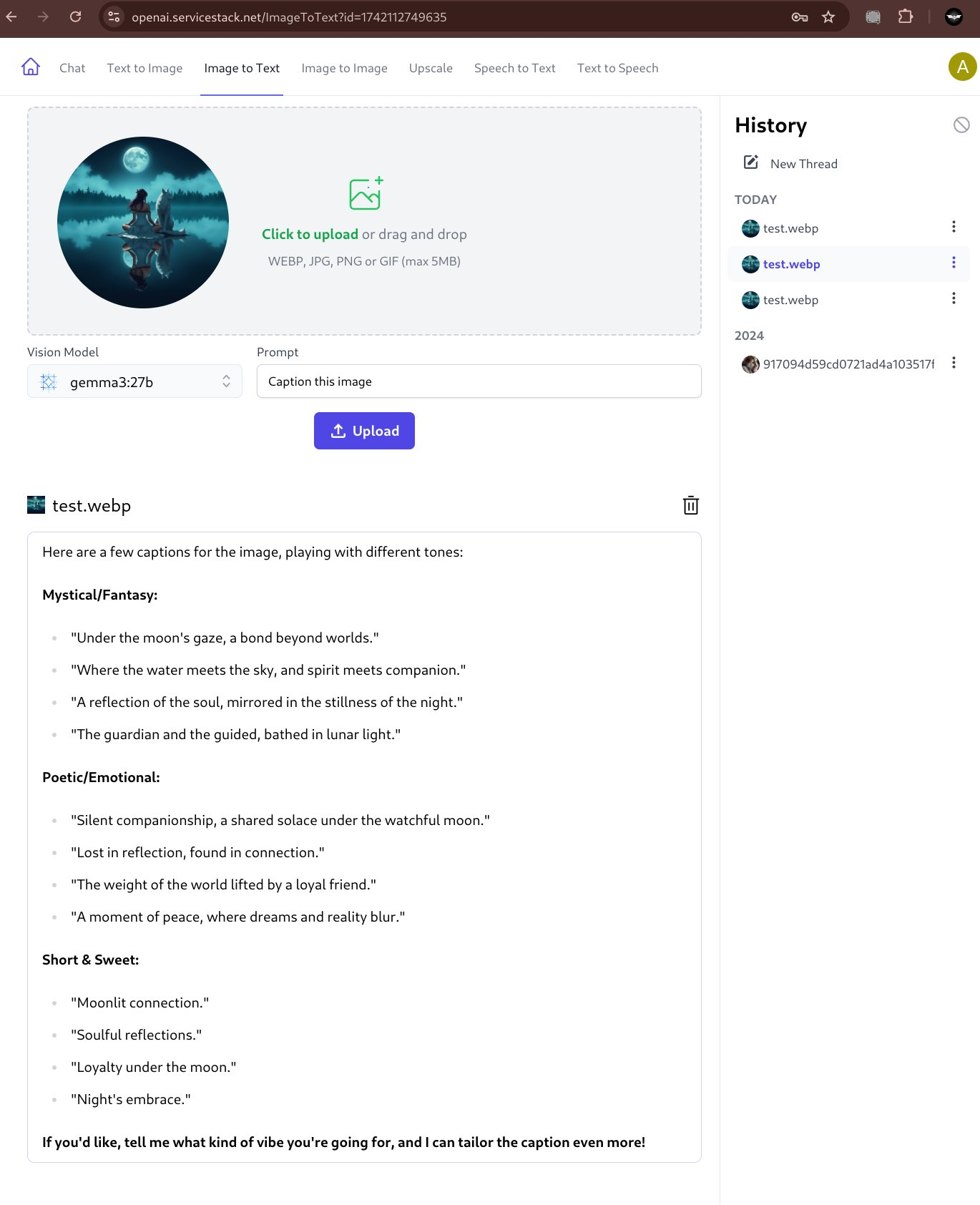
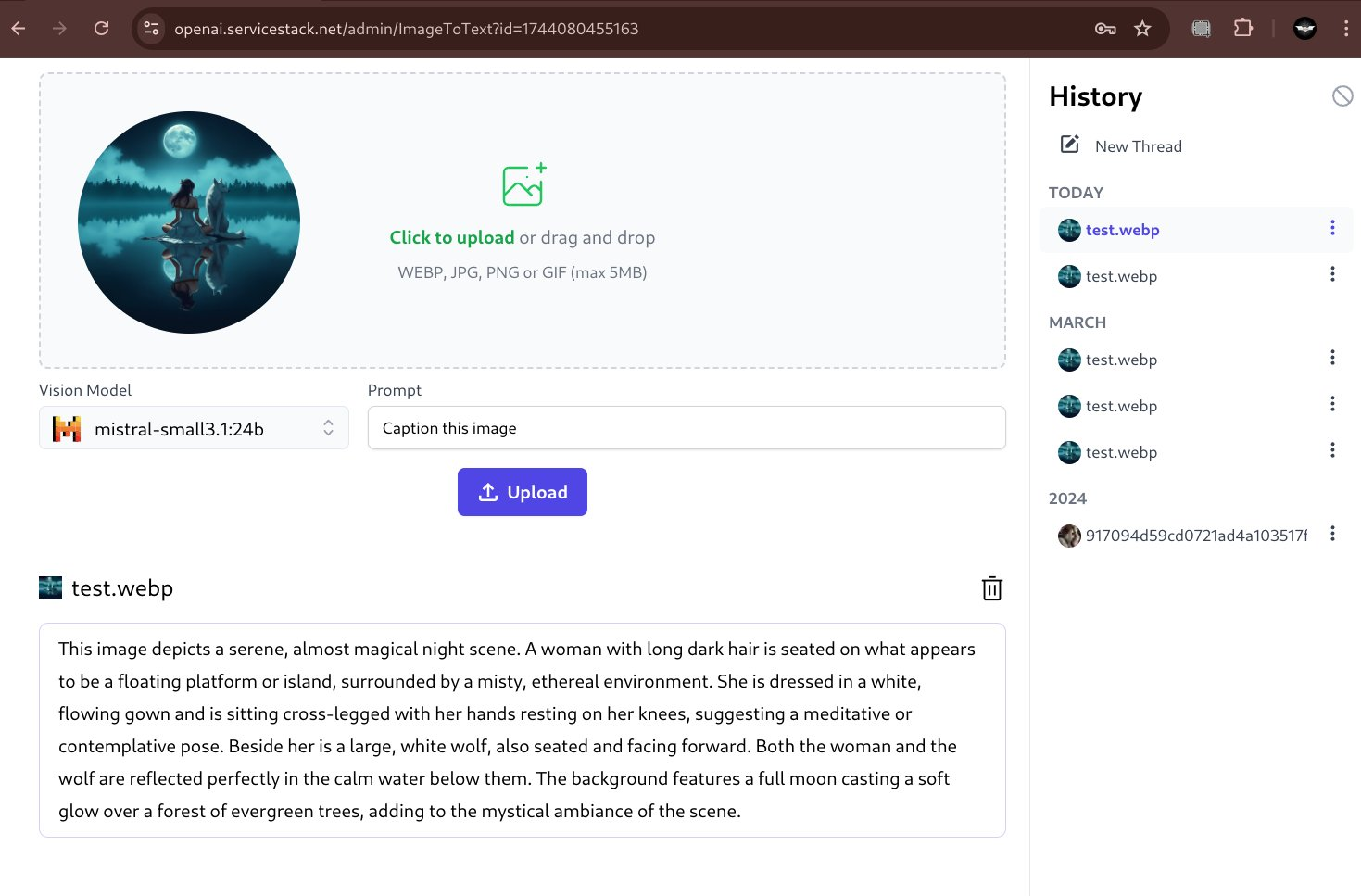
Caption Image
Although our initial testing sees gemma being better at responding to a wide variety of different prompts, e.g:
New OllamaGenerate Endpoints
To support Ollama's vision models AI Server added a new feature pipeline around Ollama's generate completion API:
- ImageToText
- Model - Whether to use a Vision Model for the request
- Prompt - Prompt for the vision model
- OllamaGeneration: Synchronous invocation of Ollama's Generate API
- QueueOllamaGeneration: Asynchronous or Web Callback invocation of Ollama's Generate API
- GetOllamaGenerationStatus: Get the generation status of an Ollama Generate API
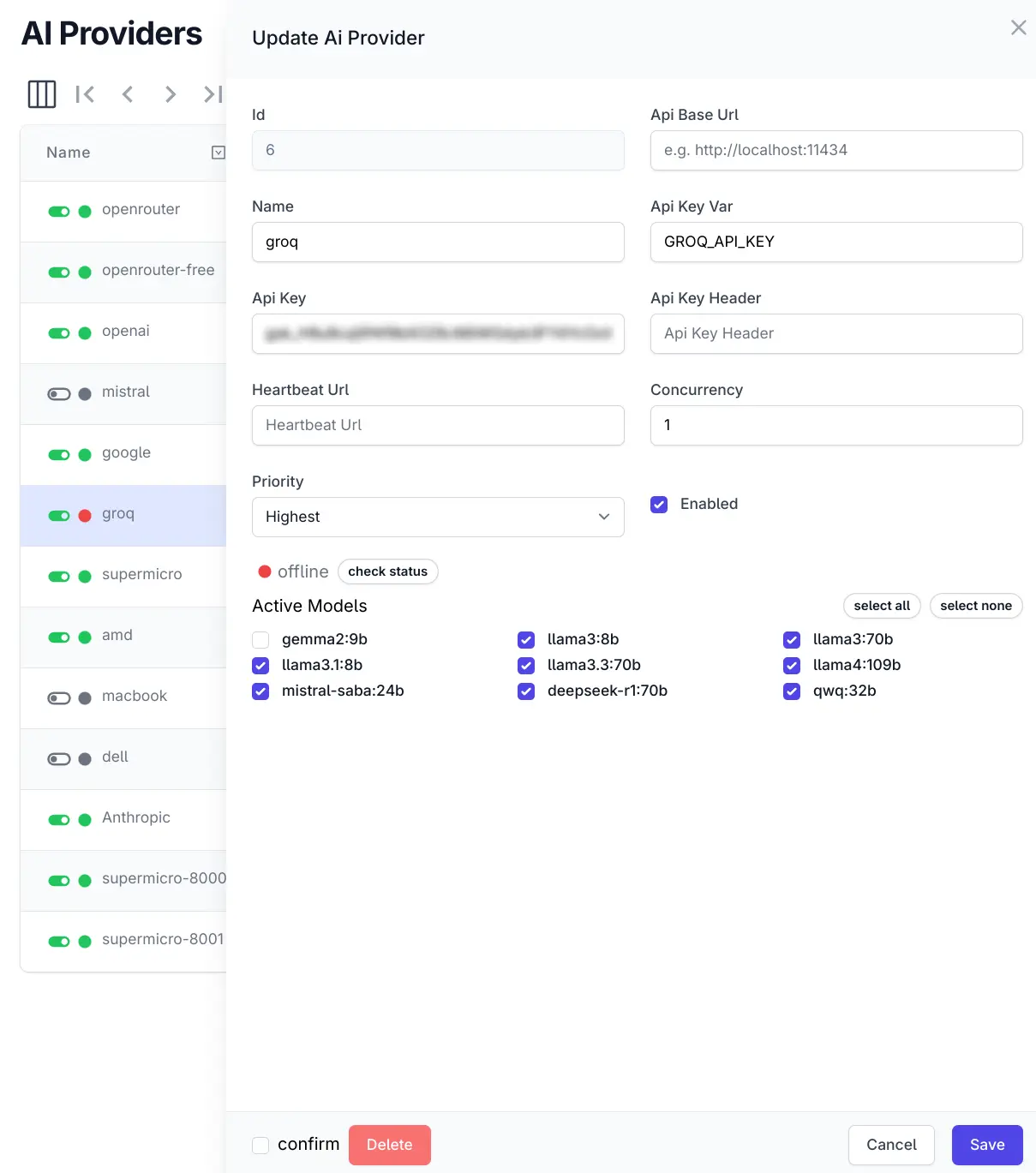
Online Status Indicator
Internally AI Server tracks which enabled providers are online and which have successive failures to trigger taking them offline. Periodically a scheduled task checks or offline providers to test whether they've come back online and their status is updated accordingly.
This status now has a green and red visible dot indicator in the AI Provider list and in the Edit form where you can manually check the online provider status:
AI Provider Status
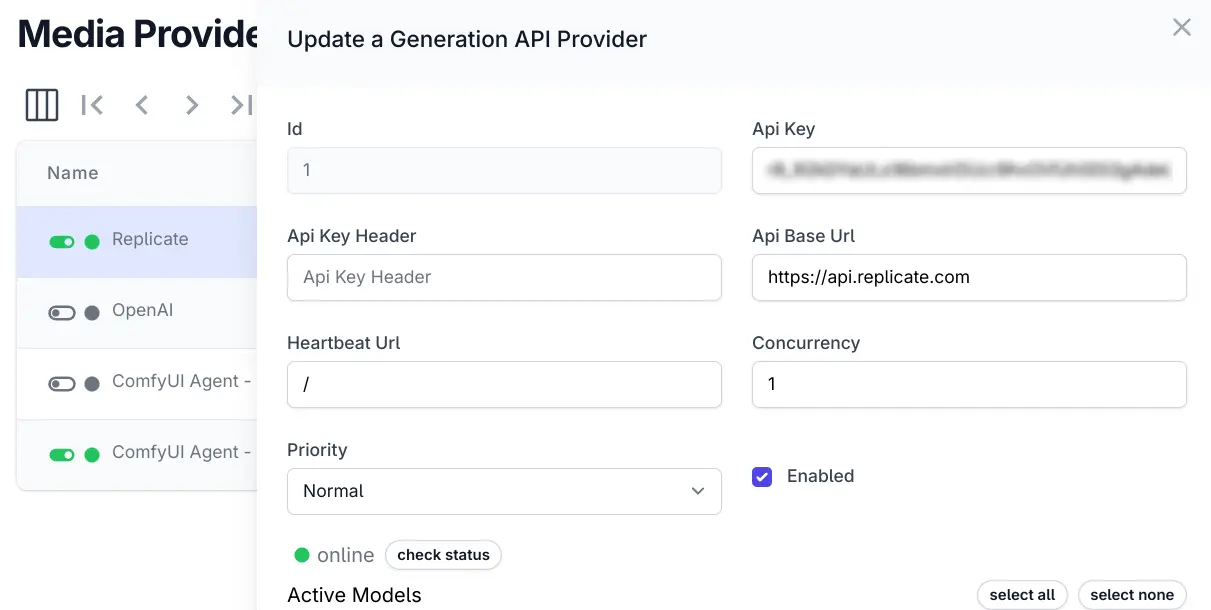
Media Provider Status
The same feature is also available on Media Providers list and Edit page:
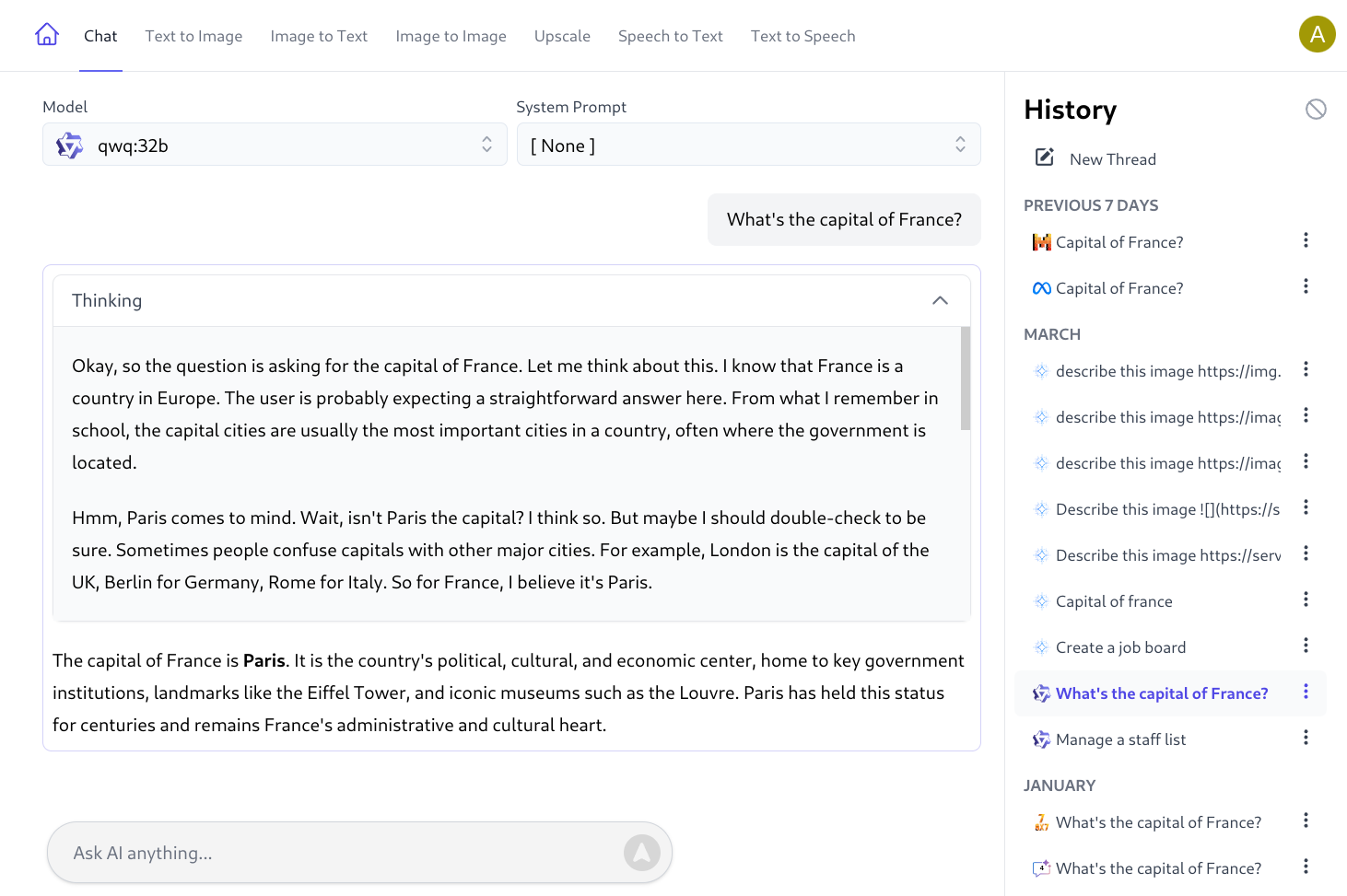
Support for Thinking Responses
With the rise and popularity of Thinking Models we've added custom rendering of thinking responses in a collapsible and scrollable container: