Self Hosted AI Server for LLMs, Ollama, Comfy UI & FFmpeg


AI Server now ready to serve!
We're excited to announce the first release of AI Server - a Free OSS self-hosted Docker private gateway to manage API access to multiple LLM APIs, Ollama endpoints, Media APIs, Comfy UI and FFmpeg Agents.
Centralized Management
Designed as a one-stop solution to manage an organization's AI integrations for all their System Apps, by utilizing developer friendly HTTP JSON APIs that supports any programming language or framework.

Distribute load across multiple Ollama, Open AI Gateway and Comfy UI Agents
It works as a private gateway to process LLM, AI and image transformations requests that any of our Apps need where it dynamically load balances requests across our local GPU Servers, Cloud GPU instances and API Gateways running multiple instances of Ollama, Open AI Chat, LLM Gateway, Comfy UI, Whisper and ffmpeg providers.
In addition to maintaining a history of AI Requests, it also provides file storage for its CDN-hostable AI generated assets and on-the-fly, cacheable image transformations.
Native Typed Integrations
Uses Add ServiceStack Reference to enable simple, native typed integrations for most popular Web, Mobile and Desktop languages including: C#, TypeScript, JavaScript, Python, Java, Kotlin, Dart, PHP, Swift, F# and VB.NET.
Each AI Feature supports multiple call styles for optimal integration of different usages:
- Synchronous API · Simplest API ideal for small workloads where the Response is returned in the same Request
- Queued API · Returns a reference to the queued job executing the AI Request which can be used to poll for the API Response
- Reply to Web Callback · Ideal for reliable App integrations where responses are posted back to a custom URL Endpoint
Live Monitoring and Analytics
Monitor performance and statistics of all your App's AI Usage, real-time logging of executing APIs with auto archival of completed AI Requests into monthly rolling SQLite databases.
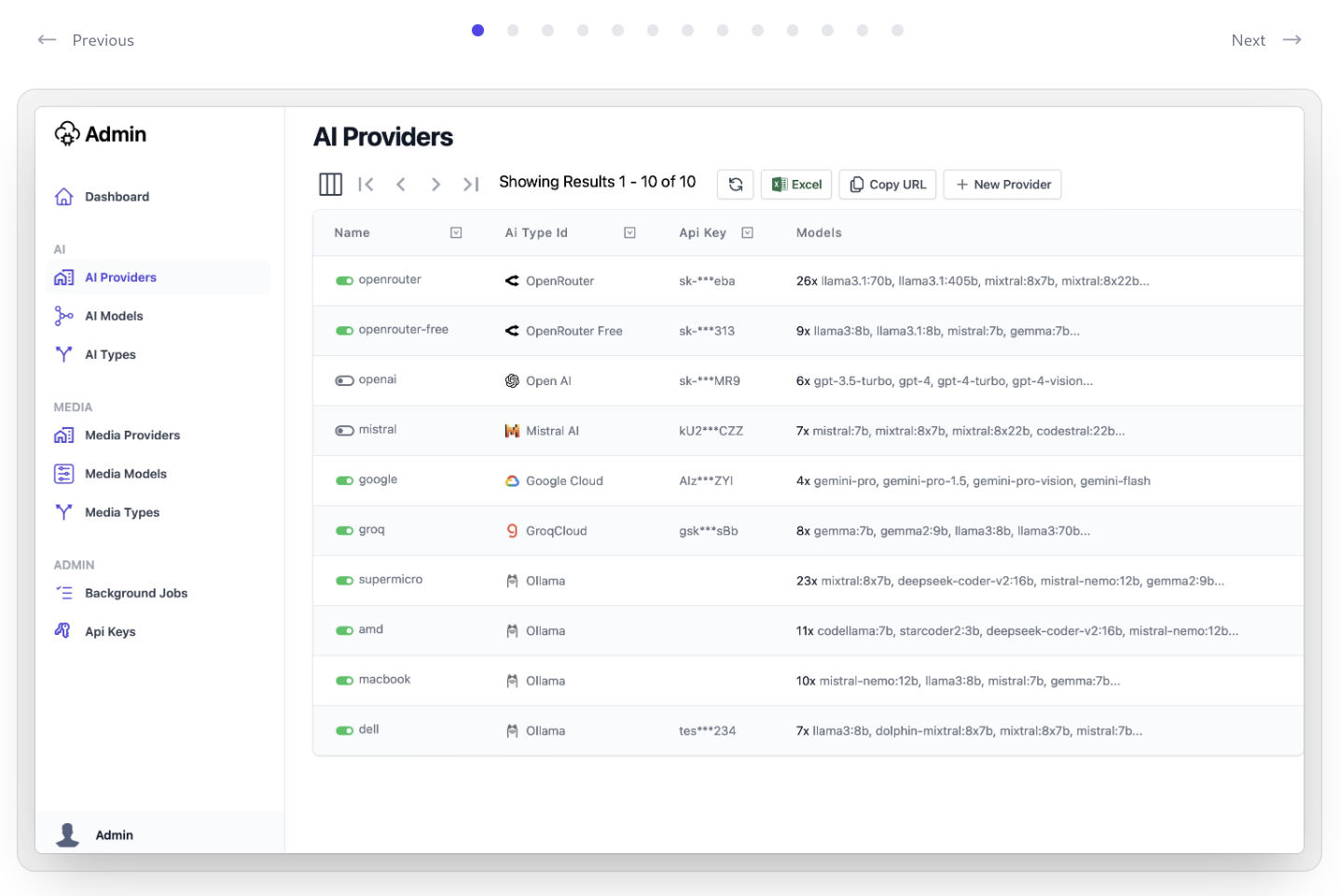
Protected Access with API Keys
AI Server utilizes Simple Auth with API Keys letting Admins create and distribute API Keys to only allow authorized clients to access their AI Server's APIs, which can be optionally further restricted to only allow access to specific APIs.
Install
AI Server can be installed on macOS and Linux with Docker by running install.sh:
- Clone the AI Server repository from GitHub:
git clone https://github.com/ServiceStack/ai-server
- Run the Installer
cd ai-server && cat install.sh | bash
The installer will detect common environment variables for the supported AI Providers like OpenAI, Google, Anthropic, and others, and prompt ask you if you want to add them to your AI Server configuration.
Optional - Install ComfyUI Agent
If your server also has a GPU you can ask the installer to also install the ComfyUI Agent:
The ComfyUI Agent is a separate Docker agent for running ComfyUI, Whisper and FFmpeg on servers with GPUs to handle AI Server's Image and Video transformations and Media Requests, including:
- Text to Image
- Image to Text
- Image to Image
- Image with Mask
- Image Upscale
- Speech to Text
- Text to Speech
Comfy UI Agent Installer
To install the ComfyUI Agent on a separate server (with a GPU), you can clone and run the ComfyUI Agent installer on that server instead:
- Clone the Comfy Agent
git clone https://github.com/ServiceStack/agent-comfy.git
- Run the Installer
cd agent-comfy && cat install.sh | bash
Running in Production
We've been developing and running AI Server for several months now, processing millions of LLM and Comfy UI Requests to generate Open AI Chat Answers and Generated Images used to populate the pvq.app and blazordiffusion.com websites.
Our production instance with more info about AI Server is available at:
API Explorer
Whilst our production instance is protected by API Keys, you can still use it to explore available APIs in its API Explorer:
Documentation
The documentation for AI Server is being maintained at:
Built-in UIs
Built-in UIs allow users with API Keys access to custom UIs for different AI features
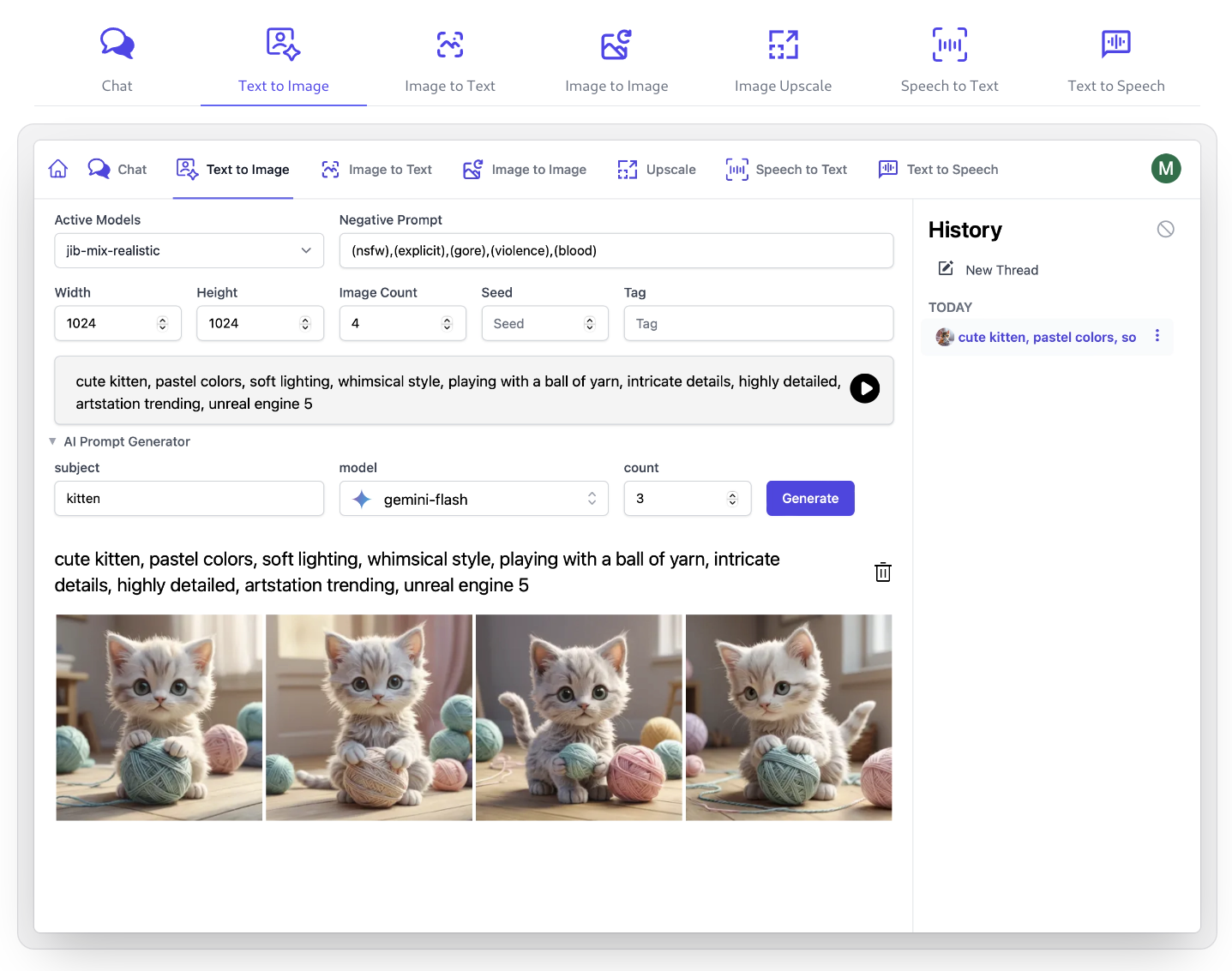
Admin UIs
Use Admin UI to manage API Keys that can access AI Server APIs and Features
Features
The current release of AI Server supports a number of different modalities, including:
Large Language Models
- Open AI Chat
- Support for Ollama endpoints
- Support for Open Router, Anthropic, Open AI, Mistral AI, Google and Groq API Gateways
Comfy UI Agent / Replicate / DALL-E 3
Comfy UI Agent
FFmpeg
-
- Crop Image - Crop an image to a specific size
- Convert Image - Convert an image to a different format
- Scale Image - Scale an image to a different resolution
- Watermark Image - Add a watermark to an image
-
- Crop Video - Crop a video to a specific size
- Convert Video - Convert a video to a different format
- Scale Video - Scale a video to a different resolution
- Watermark Video - Add a watermark to a video
- Trim Video - Trim a video to a specific length
Managed File Storage
- Blob Storage - isolated and restricted by API Key
AI Server API Examples
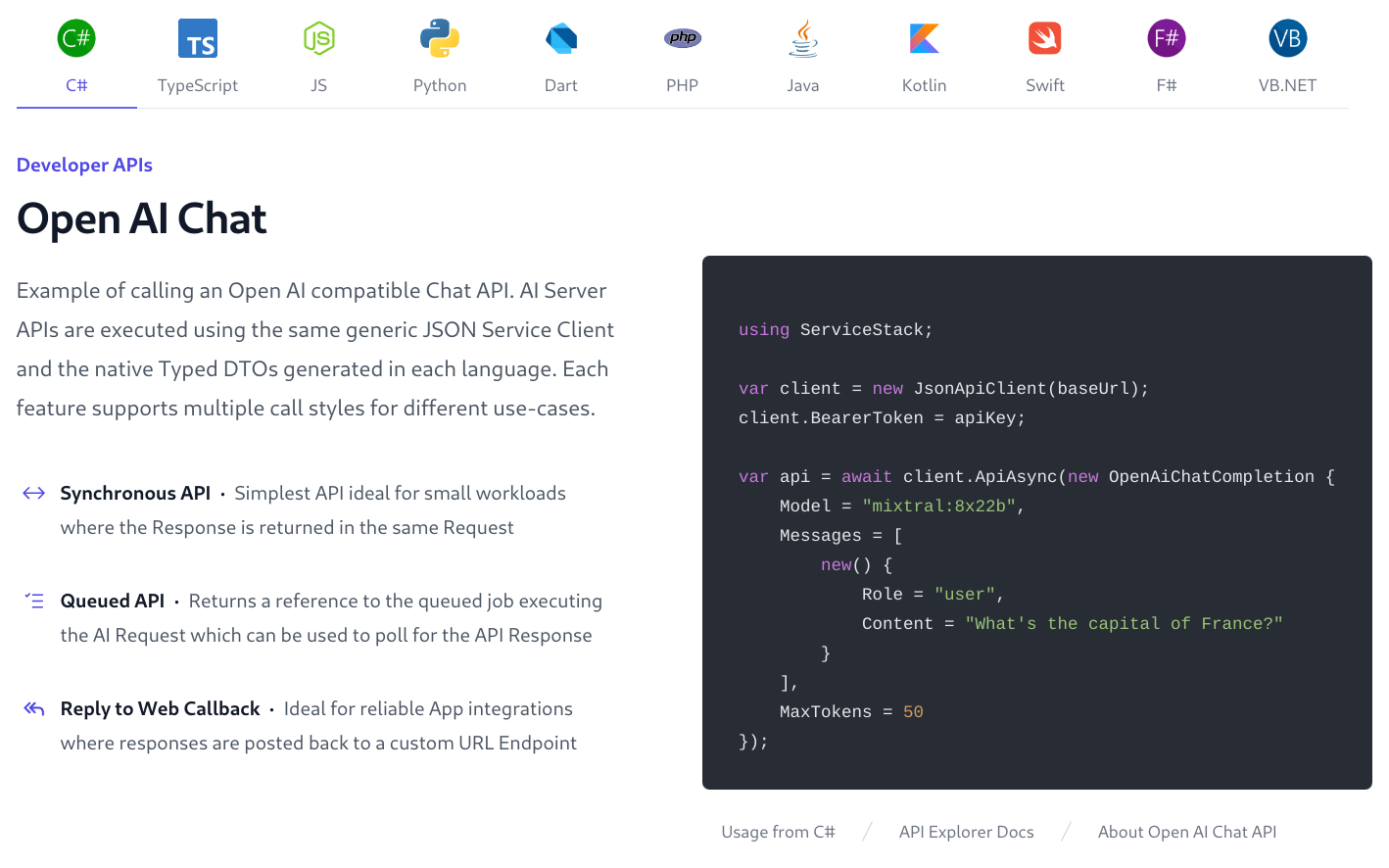
To simplify integrations with AI Server each API Request can be called with 3 different call styles to better support different use-cases and integration patterns.
Synchronous Open AI Chat Example
The Synchronous API is the simplest API ideal for small workloads where the Response is returned in the same Request:
var client = new JsonApiClient(baseUrl);
client.BearerToken = apiKey;
var response = client.Post(new OpenAiChatCompletion {
Model = "mixtral:8x22b",
Messages = [
new() {
Role = "user",
Content = "What's the capital of France?"
}
],
MaxTokens = 50
});
var answer = response.Choices[0].Message.Content;
Synchronous Media Generation Request Example
Other AI Requests can be called synchronously in the same way where its API is named after the modality
it implements, e.g. you'd instead call TextToImage to generate an Image from a Text description:
var response = client.Post(new TextToImage
PositivePrompt = "A serene landscape with mountains and a lake",
Model = "flux-schnell",
Width = 1024,
Height = 1024,
BatchSize = 1
});
File.WriteAllBytes(saveToPath, response.Results[0].Url.GetBytesFromUrl());
Queued Open AI Chat Example
The Queued API immediately Returns a reference to the queued job executing the AI Request:
var response = client.Post(new QueueOpenAiChatCompletion
{
Request = new()
{
Model = "gpt-4-turbo",
Messages = [
new() { Role = "system", Content = "You are a helpful AI assistant." },
new() { Role = "user", Content = "How do LLMs work?" }
],
MaxTokens = 50
}
});
Which can be used to poll for the API Response of any Job by calling GetOpenAiChatStatusResponse
and checking when its state has finished running to get the completed OpenAiChatResponse:
GetOpenAiChatStatusResponse status = new();
while (status.JobState is BackgroundJobState.Started or BackgroundJobState.Queued)
{
status = await client.GetAsync(new GetOpenAiChatStatus { RefId = response.RefId });
await Task.Delay(1000);
}
var answer = status.Result.Choices[0].Message.Content;
Queued Media Artifact Generation Request Example
Most other AI Server Requests are Artifact generation requests which would instead call
GetArtifactGenerationStatus to get the artifacts response of a queued job, e.g:
var response = client.Post(new QueueTextToImage {
PositivePrompt = "A serene landscape with mountains and a lake",
Model = "flux-schnell",
Width = 1024,
Height = 1024,
BatchSize = 1
});
// Poll for Job Completion Status
GetArtifactGenerationStatusResponse status = new();
while (status.JobState is BackgroundJobState.Queued or BackgroundJobState.Started)
{
status = client.Get(new GetArtifactGenerationStatus { JobId = response.JobId });
Thread.Sleep(1000);
}
File.WriteAllBytes(saveToPath, status.Results[0].Url.GetBytesFromUrl());
Queued Media Text Generation Request Example
Whilst the Media API Requests that generates text like SpeechToText or ImageToText would instead call
GetTextGenerationStatus to get the text response of a queued job, e.g:
using var fsAudio = File.OpenRead("files/test_audio.wav");
var response = client.PostFileWithRequest(new QueueSpeechToText(),
new UploadFile("test_audio.wav", fsAudio, "audio"));
// Poll for Job Completion Status
GetTextGenerationStatusResponse status = new();
while (status.JobState is BackgroundJobState.Started or BackgroundJobState.Queued)
{
status = client.Get(new GetTextGenerationStatus { RefId = response.RefId });
Thread.Sleep(1000);
}
var answer = status.Results[0].Text;
Open AI Chat with Callback Example
The Queued API also accepts a Reply to Web Callback for a more reliable push-based App integration where responses are posted back to a custom URL Endpoint:
var correlationId = Guid.NewGuid().ToString("N");
var response = client.Post(new QueueOpenAiChatCompletion
{
//...
ReplyTo = $"https://example.org/api/OpenAiChatResponseCallback?CorrelationId=${correlationId}"
});
Your callback can add any additional metadata on the callback to assist your App in correlating the response with
the initiating request which just needs to contain the properties of the OpenAiChatResponse you're interested in
along with any metadata added to the callback URL, e.g:
public class OpenAiChatResponseCallback : IPost, OpenAiChatResponse, IReturnVoid
{
public Guid CorrelationId { get; set; }
}
public object Post(OpenAiChatResponseCallback request)
{
// Handle OpenAiChatResponse callabck
}
Unless your callback API is restricted to only accept requests from your AI Server, you should include a
unique Id like a Guid in the callback URL that can be validated against an initiating request to ensure
the callback can't be spoofed.
Feedback
Feel free to reach us at ai-server/discussions with any AI Server questions.



